python | Pandas库数据预处理-重复值篇:drop_duplicates()函数及其subset参数、keep参数
相关文章
python | Pandas库数据预处理-缺失值篇:info()、isnull()、dropna()、fillna()函数 https://blog.csdn.net/m0_61523149/article/details/124009296
https://blog.csdn.net/m0_61523149/article/details/124009296
目录
原数据
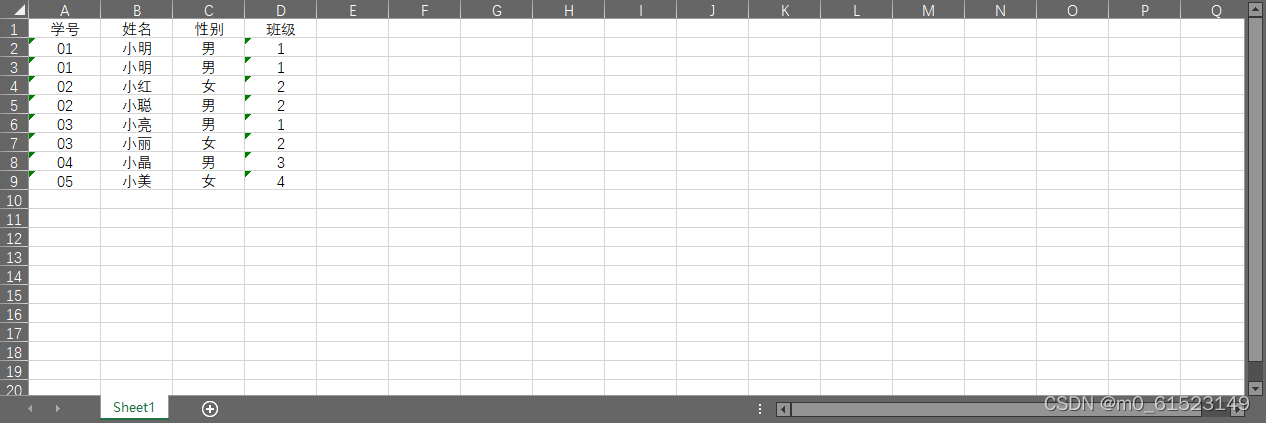
导入数据
import pandas as pd
student = pd.read_excel(r'E:\2022Python\重复值数据.xlsx')
# 原数据
print(student)输出结果如下:
学号 姓名 性别 班级
0 1 小明 男 1
1 1 小明 男 1
2 2 小红 女 2
3 2 小聪 男 2
4 3 小亮 男 1
5 3 小丽 女 2
6 4 小晶 男 3
7 5 小美 女 4drop_duplicates():去重函数
# 按所有列去重,默认保留第一个
print(student.drop_duplicates())输出结果如下:
学号 姓名 性别 班级
0 1 小明 男 1
2 2 小红 女 2
3 2 小聪 男 2
4 3 小亮 男 1
5 3 小丽 女 2
6 4 小晶 男 3
7 5 小美 女 4subset参数:设置去重参照列
# 按某几列去重,默认保留第一个
print(student.drop_duplicates(subset=['学号', '班级']))
# 按某一列去重,默认保留第一个
print(student.drop_duplicates(subset='学号'))输出结果如下:
学号 姓名 性别 班级
0 1 小明 男 1
2 2 小红 女 2
4 3 小亮 男 1
5 3 小丽 女 2
6 4 小晶 男 3
7 5 小美 女 4
学号 姓名 性别 班级
0 1 小明 男 1
2 2 小红 女 2
4 3 小亮 男 1
6 4 小晶 男 3
7 5 小美 女 4keep参数:设置去重要保留的数据
# 'first':保留第一个
print(student.drop_duplicates(keep='first'))
# 'last':保留最后一个
print(student.drop_duplicates(keep='last'))
# False:全部不保留
print(student.drop_duplicates(keep=False))输出结果如下:
学号 姓名 性别 班级
0 1 小明 男 1
2 2 小红 女 2
3 2 小聪 男 2
4 3 小亮 男 1
5 3 小丽 女 2
6 4 小晶 男 3
7 5 小美 女 4
学号 姓名 性别 班级
1 1 小明 男 1
2 2 小红 女 2
3 2 小聪 男 2
4 3 小亮 男 1
5 3 小丽 女 2
6 4 小晶 男 3
7 5 小美 女 4
学号 姓名 性别 班级
2 2 小红 女 2
3 2 小聪 男 2
4 3 小亮 男 1
5 3 小丽 女 2
6 4 小晶 男 3
7 5 小美 女 4