select、poll和epoll的区别
概要
在Unix五种I/O模型一文中,提到了I/O多路复用模型,其在Linux下有3种实现方式:select、poll、epoll,本文主要深入介绍下它们各自特点。
事先说明:I/O多路复用模型,select和poll核心就是【轮询+内核I/O事件就绪通知】,epoll的核心是内核I/O事件就绪通知。
多路:多个socket连接(即多个客户端连接)
复用:允许内核监听多个socket描述符,一旦发现进程指定的一个或多个scoket的I/O事件就绪(TCP三次握手成功[accept]、可读[read],可写[write]等),就通知该进程
要想更好的了解,最好根据代码来说,下面是代码的基本框架:
void main(int argc, char **argv)
{
int listenfd, connfd;
struct sockaddr_in srv_addr;
//创建socket套接字
if ((listenfd = socket(AF_INET, SOCK_STREAM, 0)) == -1)
{
printf("create socket error: %s(errno: %d)\n", strerror(errno), errno);
return;
}
//设置绑定地址的内容
memset(&srv_addr, 0, sizeof(srv_addr));
srv_addr.sin_family = AF_INET; //ipv4
srv_addr.sin_addr.s_addr = htonl(INADDR_ANY);//ip 0.0.0.0
srv_addr.sin_port = htons(8888); //端口
//绑定地址
if (bind(listenfd, (struct sockaddr *)&srv_addr, sizeof(srv_addr)) == -1)
{
printf("bind socket error: %s(errno: %d)\n", strerror(errno), errno);
return;
}
//listen
if (listen(listenfd, SOMAXCONN) == -1) //指定监听的套接字描述符、TCP半连接和全连接队列大小
{
printf("listen socket error: %s(errno: %d)\n", strerror(errno), errno);
return;
}
//【在这个区域分别使用阻塞,多线程,select,poll,epoll等多种方式实现连接】
close(listenfd); //关闭listen socket
return;
}
PS:基于Linux内核V6.7
一、多路复用I/O模型的诞生
之所以诞生多路复用I/O模型,肯定是旧的I/O模型无法满足需要了,首先回顾下基础的阻塞I/O模型:
代码如下:
char buff[MAXLNE];
int n;
struct sockaddr_in cli_addr;
socklen_t len = sizeof(client);
if ((connfd = accept(listenfd, (struct sockaddr *)&cli_addr, &len)) == -1)
{
printf("accept socket error: %s(errno: %d)\n", strerror(errno), errno);
return;
}
while(1)
{
n = recv(connfd, buff, MAXLNE, 0); //阻塞
if (n > 0)
{
//加上字符串的尾部,以便显示和转发
buff[n] = '\0';
printf("recv msg: %s \n", buff);
send(connfd, buff, n, 0);
}
else if (n == 0)
{
close(connfd); //关闭client socket连接
}
else //n==-1
{
printf("recv errno: %d\n", errno);
}
}
此时while在accept API之后,那么只能处理一个client,并维持长连接。
那么while在accept API之前会如何呢,显而易见,此时能处理多个client,但只能处理每个client一条消息,不能未出长连接。
如果想与多个client维持长连接,该如何做呢?于是基于阻塞I/O模型有了以下两种方式:
- 多线程或进程;
- 通过数组,链表等方式保存socket fd,不断轮询;
1.1 多线程或进程方式
代码如下(以多进程为例):
signal(SIGCHLD, sig_child); //注册子进程退出处理函数
pid_t child_pid;
while(1)
{
struct sockaddr_in cli_addr;
socklen_t len = sizeof(client);
if ((connfd = accept(listenfd, (struct sockaddr *)&cli_addr, &len)) == -1)
{
printf("accept socket error: %s(errno: %d)\n", strerror(errno), errno);
return;
}
if ((child_pid = fork()) == 0) //为每个client派生一个子进程处理
{
close(listenfd);
str_echo(connfd);
exit(0);
}
}
子进程处理客户端请求函数
void str_echo(int connfd)
{
int n;
char buff[MAXLNE];
again:
while ((n = recv(connfd, buf, MAXLINE)) > 0)
{
printf("recv msg: %s \n", buff);
send(sockfd, buf, n);
}
if (n < 0 && errno == EINTR)
{
goto again;
}
else if (n == 0)
{
close(connfd); //结束
return; //退出进程
}
else //n==-1
{
printf("recv errno: %d\n", errno);
}
}
子进程退出函数
void sig_child(int signo)
{
pid_t pid;
int stat;
//等待所有子进程退出
while ((pid = waitpid(-1, &stat, WNOHANG)) > 0)
printf("child %d exit\n", pid);
return;
}
但是这方式有个弊端,每个client由一个进程/线程去处理,系统开销相当大,很难维持大量客户端。
1.2 通过数组,链表等方式保存socket fd,不断轮询
这种模式是将客户端socket fd通过数组,链表等方式保存下来,然后不断地轮询,如果客户端太多,轮询也是很慢的。
伪代码如下:
int client_fds[FD_SETSIZE];
int sockfd;
while(1)
{
int connfd = accept() //阻塞
for (i = 0; i < FD_SETSIZE; i++) {
if (client[i] < 0) {
client_fds[i] = connfd;
break;
}
}
for (i = 0; i < FD_SETSIZE; i++) {
if ((sockfd = client_fds[i]) <= 0)
{
continue;
}
n = recv(sockfd, buf, MAXLINE)//阻塞
if(n > 0)
{
printf("recv msg: %s \n", buff);
send(sockfd, buf, n);
}
else if (n < 0 )
{
printf("recv fd:%d, errno: %d\n", sockfd, errno);
}
else// n == 0
{
close(connfd); //结束
client_fds[i] = 0; //标记一下
}
}
}
可以看到通过client_fds数组将客户端连接的描述符保存下来,后续对其进行轮询,来达到与多个client维持长连接的目的。
但accept,recv等函数都是阻塞的,如果此时I/O事件(比如accept的TCP三次握手成功,recv的可读,send的可写)没就绪,那岂不永远卡死了。所以我们需要一种机制,告诉我们client_fds数组和监听socket listenfd中哪些socket有I/O就绪事件,基于此多路复用I/O模型诞生了,没错,该模型本质就是告诉进程哪些socket有I/O就绪事件,然后我们基于此去轮询那些有I/O就绪事件的scoket,这样就不会卡住了。
PS:这种方式是没有实际应用的,主要是为了引出多路复用I/O模型。
那select、poll、epoll是如何告诉进程哪些socket有I/O就绪事件呢?下面依次探究下吧。
二、select
select api函数(还有个pselect函数,不是很常用,不过二者核心逻辑是一样的):
int select(int nfds, fd_set *readfds, fd_set *writefds,fd_set *exceptfds, struct timeval *timeout);
参数:
nfds:最大的文件描述符加1
readfds:监听可读集合
writefds:监听可写集合
exceptfds:监听异常集合
timeout:超时时间
返回值:
大于0,表示I/O就绪事件的socket描述符个数;
等于0表示没有描述符有状态变化,并且调用超时;
小于0表示出错,此时全局变量errno保存错误码。
我们使用Glibc库select或pselect函数时,都会走Linux内核do_select函数,可以看到本质就是轮询readfds、writefds、exceptfds这三个集合,每次调用会轮询两次:
- 第一次会将当前进程(本质是I/O事件就绪时的回调函数)加入到readfds、writefds、exceptfds这三个集合中socket的等待队列中(socket有I/O事件就会触发回调函数),然后就通过poll_schedule_timeout函数挂起;
- 一旦有某个socket描述符I/O事件就绪,会立即通知进程,就会开始第二次轮询,本次轮询会确定readfds、writefds、exceptfds这三个集合中到底是哪些socket描述符有就绪的I/O事件;
- 明明两次,为啥会有三呢,这里主要是在do_select最后会调用一次
poll_freewait函数,该函数会将当前进程从readfds、writefds、exceptfds这三个集合中socket的等待队列中移除。
从上面描述就可以看出,select主要工作:维护所有socket的监听(添加【步骤1】和移除【步骤三】)、判定是否有I/O事件就绪的socket。
该方式虽相比基于阻塞I/O的多进程/线程方式能更便捷的实现与多个客户端维持长连接了,但缺点多多:
- 由于无法准确识别哪些socket描述符I/O事件就绪,所以会进行无差别轮询,时间复杂度O(N);
- Linux下readfds、writefds、exceptfds这三个集合大小默认1024,所以维持长连接的客户端数量是有限的,源码如下:
typedef __kernel_fd_set fd_set
__kernel_fd_set
#undef __FD_SETSIZE
#define __FD_SETSIZE 1024
typedef struct {
unsigned long fds_bits[__FD_SETSIZE / (8 * sizeof(long))];
} __kernel_fd_set;
可以看到无论32位还是64位操作系统下fds_bits大小都是1024位,注意fd_set集合是通过位图表示第几个scoket描述符有无I/O事件。
- 每次调用select函数,都需要把所有fd_set从用户空间拷贝到内核空间,如果fd_set比较大,对性能影响就非常大;
优点:
- 相比基于阻塞I/O的多进程/线程方式,更便捷的实现与多个客户端维持长连接;
- 相比非阻塞I/O,主动轮询socket是否有I/O事件,调整为等待内核通知,这样一次系统调用就实现多个client事件的管理,更有优势。
综合来看相比基于阻塞I/O的多进程/线程方式优势并不大。
三、poll
随着社会发展,对网络服务能力要求越来越高,select最大连接数的限制这一弊端已经不适应了,于是诞生了poll。
poll api函数:
struct pollfd {
int fd; //要监听的文件描述符
short events; //要监听的事件
short revents; //事件结果
};
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
参数:
fds:这是一个数组,每一个数组元素表示要监听的文件描述符以及相应的事件
nfds:数组的个数
timeout:超时时间
返回值:
大于0:表示结构体数组fds中有fd描述符的状态发生变化,或可以读取、或可以写入、或出错。并且返回的值表示这些状态有变化的socket描述符的总数量;此时可以对fds数组进行遍历,以寻找那些revents不空的描述符,然后判断这个里面有哪些事件以读取数据。
等于0:表示没有描述符有状态变化,并且调用超时。
小于0:此时表示有错误发生,此时全局变量errno保存错误码。
我们使用Glibc库poll函数时,会走Linux内核do_sys_poll和do_poll函数,可以看到:
- do_sys_poll函数会将fds数组转化为
struct poll_list链表,根据代码可知结构如下图:
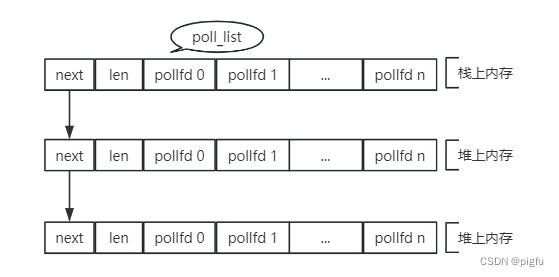
- do_poll函数被 do_sys_poll调用,其核心逻辑与do_select差不多,每次被调用会轮询两次:
1):第一次会将当前进程(本质是I/O事件就绪时的回调函数)加入到struct poll_list链表中socket的等待队列中(socket有I/O事件就会触发回调函数),然后就通过poll_schedule_timeout函数挂起;
2):一旦有某个socket描述符I/O事件就绪,会立即通知进程,就会开始第二次轮询,本次轮询会确定struct poll_list链表中到底是哪些socket描述符有就绪的I/O事件。 - do_sys_poll调用do_poll函数结束后,还有一次循环,即
poll_freewait函数,此时会将当前进程从struct poll_list链表中socket的等待队列中移除。
从上面描述就可以看出,相比select,唯一改进的地方在于没有了最大连接数的限制,但相应的也需要关注随着客户端连接数增加,轮询的效率和会急剧下降的问题。
四、epoll
随着社会发展,对网络服务能力要求更高了,poll性能也不够看了,它的缺点已经无法视而不见了,于是诞生了epoll。
epoll全名event poll,其api函数有:
- epoll_create,创建一个epoll实例
struct eventpoll,其实其返回一个int值,可以称之为epoll描述符,Linux内核会管理该值与具体epoll实例的映射关系。对应内核源码do_epoll_create
//epoll 结构体,即epoll实例
struct eventpoll {
/* 等待队列头,被sys_epoll_wait使用 */
wait_queue_head_t wq;
/* 保准准备就绪的文件描述符的一个链表 */
struct list_head rdllist;
/* 红黑树节点,epoll使用红黑树存储事件信息 */
struct rb_root rbr;
...
};
int epoll_create(int size);
参数:
size:一个int值,实际没有任何用,只要不小于等于0即可;
返回值:
小于0表示错误,此时全局变量errno保存错误码
- epoll_ctl,添加、删除、修改事件。对应内核源码do_epoll_ctl
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
参数:
epfd:epoll_create函数的返回值,即epoll描述符;
op:事件类型,EPOLL_CTL_ADD(添加事件)、EPOLL_CTL_MOD(修改事件)、EPOLL_CTL_DEL(删除事件);
fd: socket描述符;
event:告诉内核需要监听哪个事件。
返回值:
小于0表示错误,此时全局变量errno保存错误码
- epoll_wait,等待I/O事件。对应内核源码do_epoll_wait
int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout);
参数:
epfd:epoll_create函数的返回值,即epoll描述符;
events:表示准备就绪的事件数组;
maxevents: 要等待的最大事件数;
timeout:超时时间。
返回值:
大于0:表示事件就绪的socket个数。
等于0:表示没有描述符有状态变化,并且调用超时。
小于0:此时表示有错误发生,此时全局变量errno保存错误码。
根据api就可以观察出,相比select和poll,epoll拆成了三个,实际上是两个epoll_ctl和epoll_wait。即select和poll是将维护监听scoket描述符和等待I/O事件合为一体的,epoll拆开了,epoll_ctl来维护监听scoket描述符,epoll_wait来等待I/O事件。
为什么要这样做呢,在分析select和epoll缺点时,其实主要集中两点:
1:轮询:每次调用select或poll时都需要将进程加入到所有socket的等待队列中,等到socket有I/O事件立马唤醒进程,此时会轮询整个socket列表以确定哪些socket有I/O事件,最后会将进程从每个socket等队列中移除。这里涉及到对socket列表的三次轮询,随着socket列表的增加,会造成性能急剧下降的。
2:复制:每次调用select或poll时都要将整个socket列表从用户区复制到内核区,也是有一定开销的。
知道了缺点,该如何解决呢?
1:针对每次调用需要将将进程加入到所有socket的等待队列中,最后将进程从每个socket等队列中移除的操作,这部分交由epoll_ctl处理,按需对某个socket进行EPOLL_CTL_ADD、EPOLL_CTL_MOD、EPOLL_CTL_DEL操作;
2:针对每次调用都要将整个socket列表从用户区复制到内核区的问题,这部分交由epoll_create创建的epoll实例替代,epoll_ctl通过EPOLL_CTL_ADD操作,会被插入到epoll实例的红黑树中,也就是说只会被复制一次;
3:针对进程被唤醒后,还需要轮询整个socket列表以确定哪些socket有I/O事件的问题(即不知道哪些socket的I/O事件就绪,只能一个个遍历),调整成每个socket有I/O事件时会将该socket加入到epoll实例的rdllink双向链表中,进程调用epoll_wait时只需判断rdllink双向链表长度即可,大于0立即返回,等于0就挂起进程,等待被某个socketI/O事件唤醒。
所以说epoll通过对select/poll功能的拆分,解决了前两者的缺点,相对于前两者优点如下:
- 没有最大并发连接的限制,当然了还受操作系统限制,比如资源、配置等等;
- 性能高,没有了轮询,不会随着socket数量的增加而导致性能下降。
- epoll支持边缘触发(EPOLLET)和水平触发(EPOLLLT),前两者仅支持水平触发。
缺点:
目前缺点就是进程去读写I/O事件就绪的socket时,还需要将数据从内核区复制到用户区,当然了select/poll也有该问题,这一点需要异步I/O去解决了。目前epoll是够用的,Nginx,Redis都是基于epoll的,足以应对处理C10K,C100K问题。
LT(level triggered) 是 缺省 的工作方式 ,并且同时支持 block 和 no-block I/O。 在这种做法中,内核告诉你一个文件描述符是否就绪了,然后你可以对这个就绪的 fd 进行 IO 操作。如果你不作任何操作,下次内核还会继续通知你的,所以,这种模式编程出错误可能性要小一点。 select/poll 都是这种模型的代表。
ET(edge-triggered) 是高速工作方式 ,只支持 no-block I/O 。在这种模式下,当描述符从未就绪变为就绪时,内核通过 epoll 告诉你,然后它会假设你知道文件描述符已经就绪,并且不会再为那个文件描述符发送更多的就绪通知,直到你做了某些操作导致那个文件描述符不再为就绪状态了 ( 比如,你在发送,接收或者接收请求,或者发送接收的数据少于一定量时导致了一个 EWOULDBLOCK 错误)。但是请注意,如果一直不对这个 socket做 IO 操作 ( 从而使它再次变成未就绪 ) ,内核不会发送更多的通知 (only once), 不过在 TCP 协议中, ET 模式的加速效用仍需要更多的 benchmark 确认。
Epoll 工作在 ET 模式的时候,必须使用非阻塞I/O,以避免由于一个文件句柄的阻塞读 / 阻塞写操作把处理多个文件描述符的任务饿死。
五、小结
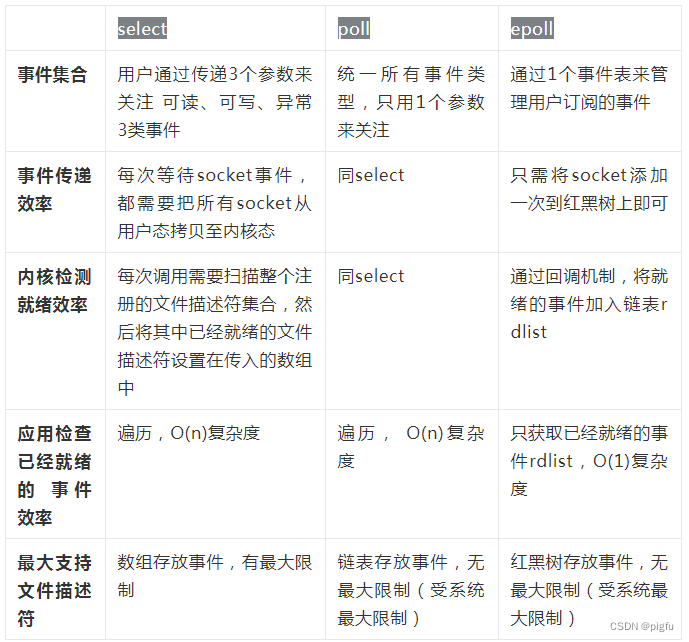
从整体来看,epoll的实现性能是比select/poll更好的,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调,一般情况下选epoll就对了。
本人研究Redis相关源码时,观察到其在Linux下就是通过epoll+EPOLLET+非阻塞I/O+Reactor设计模式组合来处理I/O事件,是其高性能的一个关键点。
六、参考
1]:Linux下实现单客户连接的tcp服务端
2]:从网络I/O模型到Netty,先深入了解下I/O多路复用
3]:epoll的本质
4]:深入了解epoll模型
5]:Linux epoll内核源码剖析