半监督学习(Semi-Supervised Learning, SSL)-简述及论文整理
- 本文参考An Overview of Deep Semi-Supervised Learning,An overview of proxy-label approaches for semi-supervised learning
- 文中相关概念补充及论文的阅读笔记将进行持续编写
机器学习主要有三种类型: 有监督, 无监督和半监督学习.
有监督学习的目标是通过训练一个函数 f f f 来预测数据的标签, 更具体地说, 给定一个包含 l l l 个标记的训练集 L d \mathbf{L}_d Ld = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x l , y l ) } \{(x_1,y_1) ,(x_2,y_2) ,\dots,(x_l,y_l)\} {(x1,y1),(x2,y2),…,(xl,yl)}, 其中 x i ∈ R n x_i \in \mathbf{R}^n xi∈Rn, i = 1 , 2 , … , l i = 1,2,\dots,l i=1,2,…,l, 训练旨在预测数据 x x x 上的标签 y y y 的函数 f f f. 很明显, 这种情况的主要特征是 L d \mathbf{L}_d Ld 子集的可用性. 分类和回归是两个主要监督学习问题, 具体取决于函数 f f f 的性质(分别针对离散和连续型 f f f).
对于无监督学习, 数据集只包含无标签的样本 U d = { ( x 1 , x 2 , x 3 , … , x u ) } \mathbf{U}_d=\{(x_1,x_2,x_3,\dots,x_u)\} Ud={(x1,x2,x3,…,xu)}, 其中 x i ∈ R n x_i \in \mathbf{R}^n xi∈Rn, i = 1 , 2 , … , u i = 1,2,\dots,u i=1,2,…,u. 同时不知道每个输入示例的预期输出. 其目标是在 U d \mathbf{U}_d Ud 子集或与其他实例有很大差异的极端实例上找到相似性——规律性, 并在没有人为干预的情况下对它们进行分类. 最常用的无监督方法是聚类, 奇异值检测及降维.
半监督学习(SSL). 让学习器不依赖外界交互、自动地利用未标记样本来提升学习性能. 即在少量样本标签的引导下, 能够充分利用大量无标签样本提高学习性能, 避免了数据资源的浪费, 同时解决了有标签样本较少时监督学习方法泛化能力不强和缺少样本标签引导时无监督学习方法不准确的问题.
基本假设
- The Smoothness Assumption
平滑假设:位于稠密数据区域的两个距离很近的样例的类标签相似,反之则趋于不同。 - The Cluster Assumption
聚类假设:输入数据点形成簇,每个簇对应于一个输出类,那么如果点在同一个簇中,则它们可以认为属于同一类。 - The Manifold Assumption
流形假设:如果高维样本恰好可以映射到一个低维的流形结构上,此时在低维的流型空间中,前两大假设仍旧是可以成立的。即输入空间由多个低维流形组成,所有数据点均位于其上;位于同一流形上的数据点具有相同标签。
基本方法
*代理标签法(Proxy-label Methods)
使用预测模型或它的某些变体生成一些代理标签,这些代理标签和有标记的数据混合一起,提供一些额外的训练信息,即使生成标签通常包含嘈杂,不能反映实际情况。这类方法主要可分为分为两类:self-training(模型本身生成代理标签)和 multi-view learning(代理标签是由根据不同数据视图训练的模型生成的)。同时 Pseudo-Label 与 self-training 十分类似。
- Self-training
自训练的主要缺点是模型无法纠正自己的错误。如果模型对未标记数据的预测是可信的但有误,那么错误的数据仍然会被纳入训练,并且模型的错误会被放大。如果未标记数据的域与标记数据的域不同,则这种影响会加剧;在这种情况下,模型的置信度将不能很好地预测其性能。Self-training 基本算法流程如下:

(1) 将带标签数据集作为训练集 ( X t r a i n , y t r a i n ) = ( X l , y l ) (\mathbf{X}_{train},y_{train})=(\mathbf{X}_l,y_l) (Xtrain,ytrain)=(Xl,yl)
(2) 从 ( X l , y l ) (\mathbf{X}_l,y_l) (Xl,yl) 中训练初始分类器 C i n t C_{int} Cint,利用 C i n t C_{int} Cint 对无标签数据集 X u \mathbf{X}_u Xu 进行预测
(3) 从 X u \mathbf{X}_u Xu 中选择最自信的样本 ( X c o n f , y c o n f ) (\mathbf{X}_{conf},y_{conf}) (Xconf,yconf),然后将 X c o n f \mathbf{X}_{conf} Xconf 从 X u \mathbf{X}_u Xu 中去掉
(4) 将 ( X c o n f , y c o n f ) (\mathbf{X}_{conf},y_{conf}) (Xconf,yconf) 加入到训练样本 ( X t r a i n , y t r a i n ) (\mathbf{X}_{train},y_{train}) (Xtrain,ytrain) 中
(5) 重复步骤4到8,直到满足停止条件
Confidence Regularized Self-Training
Uncertainty-aware Self-training for Text Classification with Few Labels
Self-training with Noisy Student improves ImageNet classification
CReST: A Class-Rebalancing Self-Training Framework for Imbalanced Semi-Supervised Learning - Pseudo-Label
Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks
IN DEFENSE OF PSEUDO-LABELING:
AN UNCERTAINTY-AWARE PSEUDO-LABEL SELECTION FRAMEWORK FOR SEMI-SUPERVISED LEARNING - Meta Pseudo Labels
Meta Pseudo Labels - Multi-view/Single-view training
数据的采集越来越呈现出多源异构特性,在越来越多的实际问题中存在着大量对应着多组数据源的样本,即多视图数据。如果使用单视图(即用所有特征组成一个特征向量),将无法选择一种既适合所有数据类型的普适学习方法,在这种情况下,使用多视图的表示法较为适合,即把数据表示成多个特征集,然后在每个特征集上可以用不同的学习方法进行学习。多视图数据可以通过不同的测量方法(例如颜色信息和纹理)收集不同的视图图片信息,或通过创建原始数据的有限视图来实现。
4.1 Co-training
协同训练同时也属于基于分歧的方法。基于分歧的方法disagreement-based methods使用多个学习器,学习器之间的分歧 disagreement 对未标记数据的利用至关重要。它的基本思想是:构造两个不同的分类器,利用小规模的标注语料,对大规模的未标注语料进行标注的方法。Co-training方法最大的优点是不用人工干涉,能够从未标注的语料中自动学习到知识。Co-training 算法利用两个不同学习器在数据集的/分割的特性集上独立学习,并结合两个学习器的学习结果作出最后学习结论,这样来达到降低错误率的目的。Co-training 基本流程如下:

Co-training 要求数据 L \mathbf{L} L 可以用两个条件独立的特征集 L 1 \mathbf{L}^1 L1 和 L 2 \mathbf{L}^2 L2 表示,并且每个特征集都足以训练一个好的模型。在初始模型 m 1 m_1 m1 和 m 2 m_2 m2 在各自的特征集上训练后,在每次迭代中,将其中一个模型更自信(即概率高于阈值 τ \tau τ )的输入 x x x 移动到另一个模型的训练集。
Combining labeled and unlabeled data with co-training
Semisupervised Regression with Cotraining-Style Algorithms
4.2 Democratic Co-training
Rather than treating different feature sets as views, democratic co-learning employs models with different inductive biases。Democratic Co-training算法流程如下:

首先在完整的标记数据 L \mathbf{L} L 上分别训练每个模型 m i m_i mi,然后模型对未标记的数据 U \mathbf{U} U 进行预测。如果大于一半的模型 M M M 同意样本的标签,则将该样本 { ( x , j ) } \{(x,j)\} {(x,j)} 添加到标记数据集中。重复此过程,直到不再添加更多样本。最终预测是通过以模型的置信区间加权的绝对多数投票法做出的。其中 M M M 是对样本 x x x 预测相同标签 j j j 的所有模型的集合。
Democratic Co-training
4.3 Tri-training
Tri-training 利用三个独立训练模型的一致性来减少对未标记数据的预测偏差。Tri-training 算法基本流程如下:

利用 bootstrap 方法从有标签数据集 L \mathbf{L} L 里采样三个子数据集 S i \mathbf{S}_i Si,利用三个子数据集训练三个有差异的基分类器 m i m_i mi。对于其中一个分类器 m i m_i mi,另外两个分类器预测未标注的数据集 x ∈ U x \in \mathbf{U} x∈U,挑选出其中预测结果相同的样本 p j ( x ) = p k ( x ) p_j(x)=p_k(x) pj(x)=pk(x),作为新的有标签数据 { ( x , p j ( x ) ) } \{(x,p_j(x))\} {(x,pj(x))},加入到分类器 m i m_i mi 的训练集中。重复步骤5到10,直到 m i m_i mi 不发生变化。
Tri-training: Exploiting unlabeled data using three classififiers
4.4 Tri-training with disagreement
带分歧的 Tri-training 中提出,模型应该只在其弱点上得到加强,并且标记数据不应该被简单的数据点扭曲。其对 Tri-training 算法中的第8行做了修改,要求对于 m j m_j mj 和 m k m_k mk 一致的未标记数据点,另一个模型 m i m_i mi 不同意预测。Tri-training with disagreement 在词性标注方面取得了有竞争力的结果。
Simple semi-supervised training of part-of-speech taggers
4.5 Asymmetric tri-training
非对称 Tri-training 在计算机视觉中的无监督域适应方面取得了最先进的结果。
Asymmetric Tri-training for Unsupervised Domain Adaptation
4.6 Multi-task tri-training
多任务 Tri-training 旨在通过利用多任务学习 (MTL) 的见解来降低三重训练的时间和空间复杂度。Multi-task tri-training 算法基本流程如下:

Strong Baselines for Neural Semi-supervised Learning under Domain Shift
4.7 Cross-View Training
Semi-supervised sequence modeling with cross-view training
*一致性正则化(Consistency Regularization)
如果对一个未标记的数据应用实际的扰动,则预测不应发生显著变化,因为在聚类假设下,具有不同标签的数据点在低密度区域分离。对于无标签图像,添加噪声之后模型预测也应该保持不变,即找到一种适合的数据增强。具体来说,给定一个未标记的数据点 x ∈ D u x \in \mathbf{D}_u x∈Du 及其扰动的形式 x ^ \hat{x} x^,目标是最小化两个输出之间的距离 d ( f θ ( x ) + f θ ( x ^ ) ) d(f_\theta(x)+f_\theta(\hat{x})) d(fθ(x)+fθ(x^)),流行的距离测量 d d d 通常是均方误差(MSE),Kullback-Leiber散度(KL)和Jensen-Shannon散度(JS)。
以下方法同时属于深度半监督学习(Deep semi-supervised learning)范畴
注意:LadderNet,VAT,Pi-modal,Mean Teacher 等算法也为 self-ensembling 范畴,即自集成,自己集成自己,仅从字面意思上看,需要融合多个结果,而对于神经网络,一个样本如果多次送入网络,能够产生多个模型预测结果,这些结果可以进行融合;同时在不同的 batch 训练之后,模型的参数也会发生变化,参数可以进行融合, 因此,self-ensembling 的套路在于集成模型预测结果或者模型参数。
- LadderNet
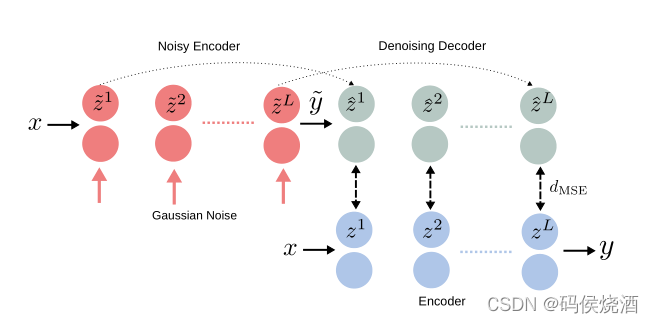
Semi-Supervised Learning with Ladder Networks - Pi-Model & Temporal Ensembling
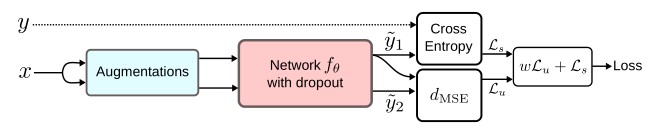
Temporal Ensembling for Semi-Supervised Learning
代码地址
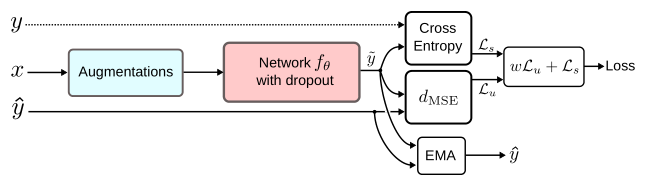
3. Mean teachers
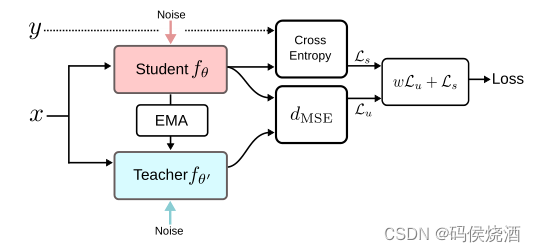
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results
代码地址
4. Dual Students
Dual Student: Breaking the Limits of the Teacher in Semi-Supervised Learning
5. Fast-SWA
6. VAT(Virtual Adversarial Training)
Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning
7. Adversarial Dropout
Adversarial Dropout for Supervised and Semi-supervised Learning
8. ICT(Interpolation consistency training)
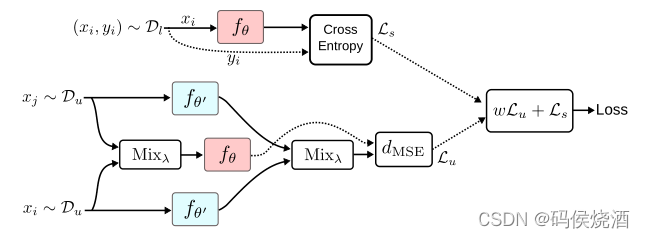
Interpolation consistency training for semi-supervised learning
9. UDA(Unsupervised Data Augmentation)
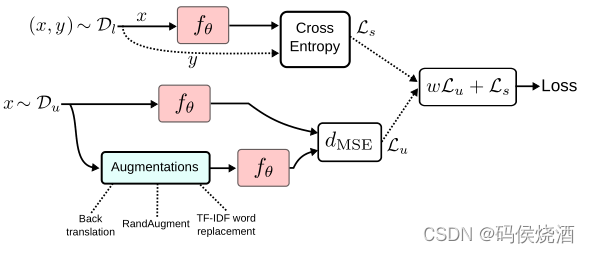
Unsupervised Data Augmentation for Consistency Training
代码地址
*Holistic Methods
Holistic Methods 试图在一个框架中整合当前的 SSL 的主要方法,从而获得更好的性能。
- MixMatch
MixMatch: A Holistic Approach to Semi-Supervised Learning - FixMatch
FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence - ReMixMatch
ReMixMatch: Semi-Supervised Learning with Distribution Alignment and Augmentation Anchoring - FeatMatch
FeatMatch: Feature-Based Augmentation for Semi-Supervised Learning - AggMatch
AggMatch: Aggregating Pseudo Labels for Semi-Supervised Learning
*生成式模型(Generative Model)
假设所有数据均由相同的生成式模型产生,借助模型参数将未标记数据与学习目标联系起来,通常利用 EM 算法根据极大似然来估计模型参数。有朴素贝叶斯、混合高斯、隐马尔可夫、贝叶斯网络等。即先对 x x x 和 y y y 的联合分布 p ( x , y ) p(x,y) p(x,y) 建模,然后通过贝叶斯公式来求得 p ( y i ∣ x ) p(y_i|x) p(yi∣x) ,然后选取 p ( y i ∣ x ) p(y_i|x) p(yi∣x) 最大时对应的 y i y_i yi,此类方法往往都需要一定的的较强的领域先验知识来假设数据服从的潜在的分布是哪一种分布,错误的分布假设只会带来更加错误的结果。
- Variational Autoencoders for SSL
1.1 Variational Autoencoder
1.2 Variational Auxiliary Autoencoder
1.3 Infinite Variational Autoencoder - Generative Adversarial Networks for SSL
2.1 CatGAN
2.2 DCGAN
2.3 SGAN
2.4 Feature Matching GAN
2.5 Bad GAN
2.6 Triple-GAN
2.7 BiGAN
2.1 CatGAN
2.1 CatGAN
*图(Graph-Based SSL)
- Graph Construction
- Label Propagation
- Graph Embedding
- Graph Neural Networks
*Entropy Minimization
熵最小化鼓励对未标记数据进行更有信心的预测,即预测应该具有低熵,而与ground truth无关(因为ground truth对于未标记数据是未知的)。伪标签(pseudo-labels)便是基于这种假设的方法,其对于未标记数据,选择预测概率最大(或置信度最大)的标记作为样本的伪标记。通过最小化未标记数据的熵,促进类之间的低密度分离。
*Self-Supervision for SSL
*低密度分离
尝试为无标签样本找到合适的标签,使得超平面划分后的间隔最大化。该假设认为决策边界应该位于低密度区域,代表S3VM,TSVM等。同时,基于一致性正则化的方法通过使网络输出对小输入扰动不变来实现这一假设。
*PU learning
在只有正类和无标记数据的情况下,训练二分类器。