实例分割总结 Instance Segmentation Summary(Center Mask、Mask-RCNN、PANNet、Deep Mask和Sharp Mask)
实例分割总结 Instance Segmentation Summary
实例分割常用网络总结
实例分割网络经常接触到有:
Mask-RCNN:基于Faster-RCNN的改进,加了一个语义分割的分支FCN网络,是自顶而下的思想(先检测到包围框实现了分类,再对每一个包围框进行语义分割。检测结果中每一个目标的标签是不同的,实现了区分不同的实例)。
PANNet:也是基于自顶而下的思想,采用自底而上的路径增强手段对特征提取网络部分进行了改进,在mask分支上增加FC辅助分割。
Deep Mask和Sharp Mask:DeepMask的技巧是把分割看成是一个海量的二进制分类问题,实现图像分割;SharpMask优化DeepMask的输出,产生具有更高保真度的能精确框定物体边界的mask;DeepMask不知道具体对象类型,尽管可以框定但不能区分物体,使用一个专门的网络架构来对每一个mask进行分类,也就是MultiPathNet。
Center Mask:是一种自底而上的one-stage实例分割网络(前面几个网络均是two-stage网络)。实现了anchor-free的效果。Center Mask同时包含一个全局显著图生成分支和一个局部形状预测分支,能够在实现像素级特征对齐的情况下实现不同物体实例的区分。
论文名称——CenterMask: single shot instance segmentation with point representation
需要说明的是:
(1) 全局显著图生成分支:预测整个图像的显著性图,实现精确分割并保留精确的空间位置,提供显著性细节,在像素级将前景与背景分离并实现像素级对齐。但是不能区分实例。
(2)局部形状预测分支:它为每个局部区域预测一个粗略的遮罩,可以自动分离不同的实例。为了实现这一点,从目标中心的点表示中提取局部形状信息。局部形状由一个粗掩模表示,该粗掩模将物体与近距离物体分开。
(3)最后,将粗糙但感知实例的局部形状和精确但不感知实例的全局显著性映射组合起来,形成最终的实例掩码。
分割线
Mask-RCNN网络
Mask R-CNN:
改进:
用FPN进行目标检测,并通过添加额外分支进行语义分割(额外分割分支和原检测分支不共享参数),即MaskR-CNN有三个输出分支(分类、坐标回归、和分割)
(1).改进了RoIpooling,通过双线性差值使候选区域和卷积特征的对齐不因量化而损失信息。
(2).在分割时,MaskR-CNN将判断类别和输出模板(mask)这两个任务解耦合,用sigmoid配合对率(logistic)损失函数对每个类别的模板单独处理,比经典分割方法用softmax让所有类别一起竞争效果更好
1、整张图片送入CNN,进行特征提取
2、在最后一层卷积featuremap上,通过RPN生成ROI,每张图片大约300个建议窗口
3、通过RoIAlign层使得每个建议窗口生成固定大小的feature map(ROIAlign是生成mask预测的关键)
4、得到三个输出向量,第一个是softmax分类,第二个是每一类的bounding box回归,第三个是每一个ROI的二进制掩码Mask(FCN生成)
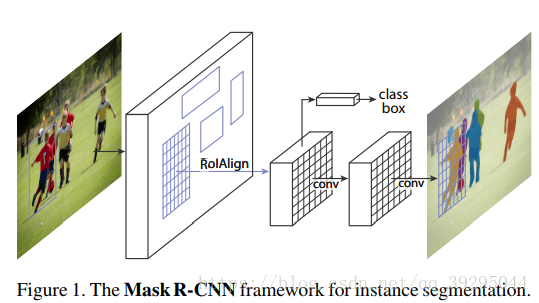
Mask Representation:
mask 编码了 输入的 object 的空间布局(spatial layout)
针对每个 RoI,采用 FCN 预测一个 m×m 的 mask.
mask 分支的每一网络层均可保持 m×m 的 object 空间布局,而不用压扁拉伸成向量形式来表示,导致空间信息损失.
pixel-to-pixel 操作需要保证 RoI 特征图的对齐性,以保留 per-pixel 空间映射关系(映射到ROI原图). 即 RoIAlign.
ROIAlign:
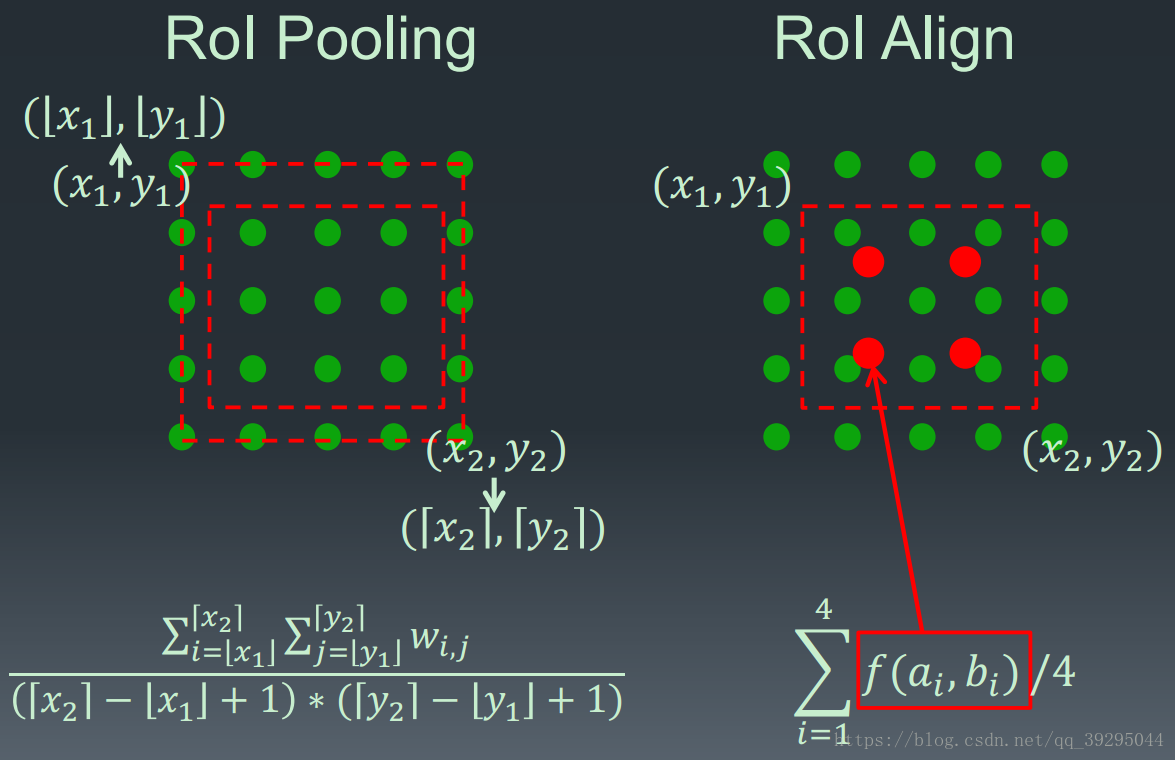
原来RoIPooling是映射原图RoI 到特征图 RoI,其间基于 stride 间隔来取整,导致将特征图RoI映射回原图RoI时,出现 stride 造成的误差(max pool 后特征图的 RoI 与原RoI 间的空间不对齐更加明显). 会影响像素级的 mask 分割. 因此需要像素级的对齐ROIAlign
RoIPool 用于从每个 RoI 中提取小的特征图的操作,RoIPool 选择的特征图区域,会与原图中的区域有轻微出入,分析ROIpool的步骤:把浮点数ROI量化到离散粒度的特征图,细分为空间直方图的bins,最后每个bin所涵盖的特征值被聚合(常用max pooling聚合)
也就是说,对浮点数 RoI 量化,再提取分块的直方图,最后利用 max pooling 组合,导致 RoI 和提取的特征间的 misalignments。对于平移不变性的分类任务影响不大,但对于要求精确的像素级 masks 预测具有较大的负影响.
RoIAlign 能够去除 RoIPool 引入的 misalignments,准确地对齐输入的提取特征. 即: 避免 RoI 边界或 bins 进行量化(如,采用 x/16x/16 来替代 rounding(x/16)rounding(x/16)[四舍五入处理] );采用 bilinear interpolation 根据每个 RoI bin 的四个采样点来计算输入特征的精确值,并采用 max 或 average 来组合结果.
如,假设点 (x,y)(x,y),取其周围最近的四个采样点,在 Y 方向进行两次插值,再在 X 方向 进行两次插值,以得到新的插值. 这种处理方式不会影响 RoI 的空间布局.
假设有一个 128x128 的图像,25x25 的特征图,想要找出与原始图像左上角 15x15 位置对应的特征区域,怎么在特征图上选取像素?
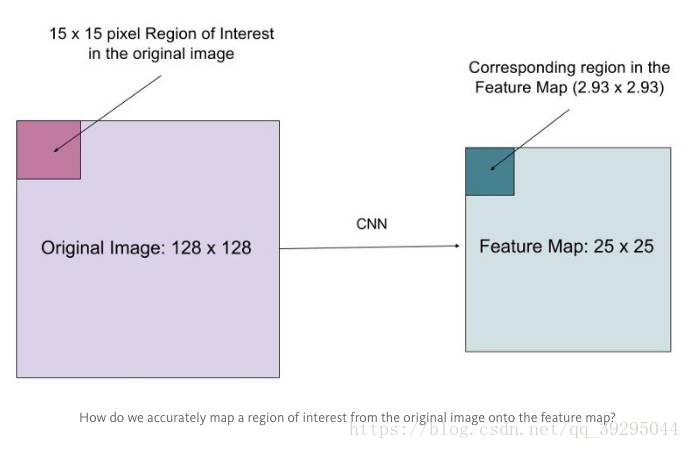
原始图像的每一个像素与特征图上的 25/128 个像素对应. 为了在原始图像选取 15 个像素,在特征图上我们需要选择 15 * 25/128 ~= 2.93 个像素.
对于这种情形,RoIPool 会舍去零头选择两个像素,导致排列问题. 但在 RoIAlign,这种去掉小数点之后数字的方式被避免,而是使用双线性插值(bilinear interpolation)准确获得 2.93 像素位置的信息,避免了排列错误.
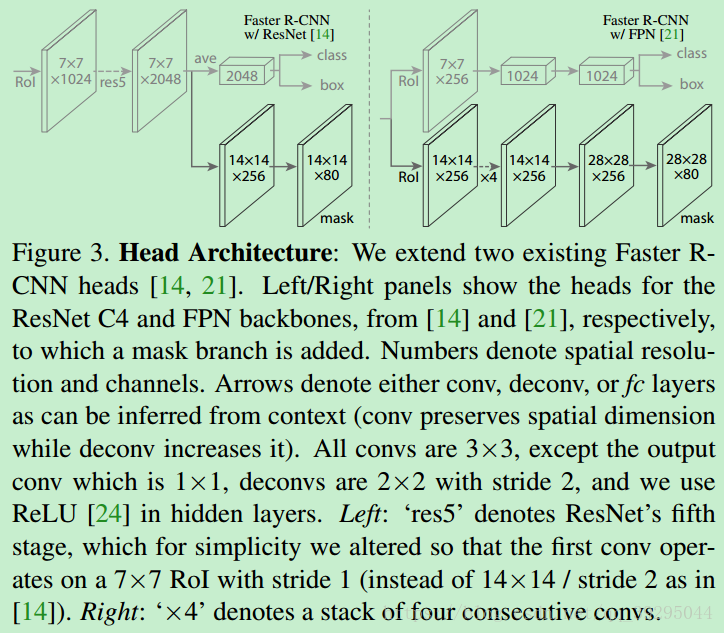
网络结构
Backbone 卷积网络 —— 用于整张图片的特征提取 ,ResNeXt-101,ResNet-50,FPN(Feature Pyramid Network).
- Backbone1:Faster R-CNN 基于 ResNets,是从第 4 stage 的最后一个卷积层提取特征,这里记为 C4,即 ResNet-50-C4,ResNeXt-101-C4.(常用的)
- Backbone2:ResNet-FPN(性能 better,对基础网络的改进,另一个改进方向)
Head 网络 —— 用于对每个 RoI 分别进行 bounding-box 识别(分类和回归) 和 Mask 预测.
分割线
PANnet
PAN:
1、整张图片送入FPN,进行特征提取
2、自下到上的通道增强将低层的信息融入高层,生成新的特征图
3、经过适应特征池化层
4、输入两个分支,得到三个输出向量,一是softmax分类&Bbox回归,二是每一个ROI的掩码Mask(FC融合)
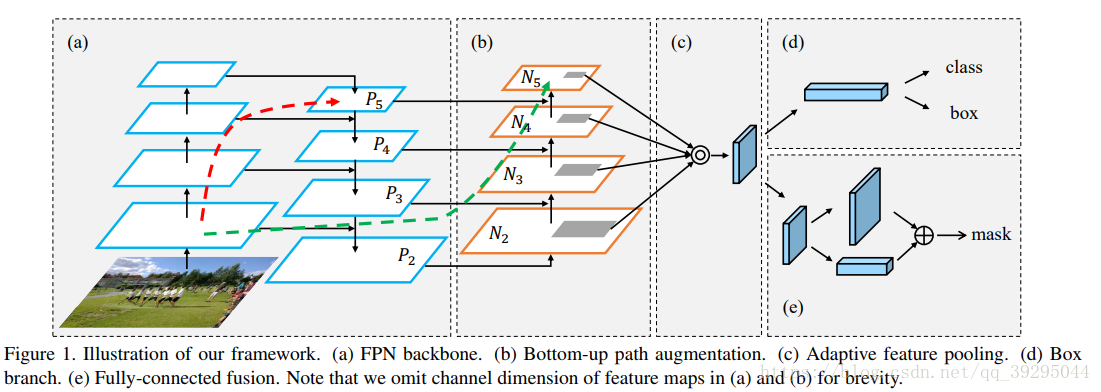
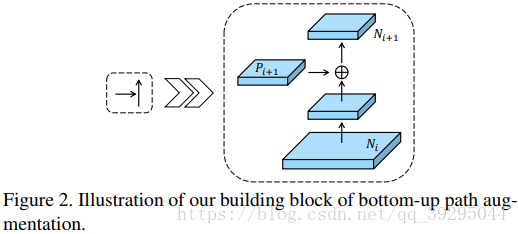
Bottom-up 路径增强:
为了加强低层信息变得更容易传播,细节利用上
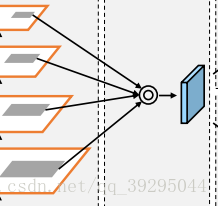
Adapting 特征池:
允许每个候选区从访问各级信息进行预测。
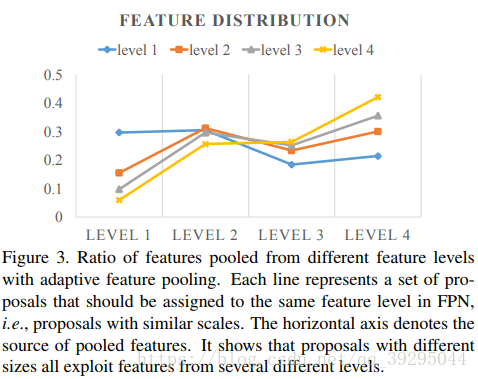
FPN中,从P2-P6(P6仅用作生成proposal,不用作RoIPooling时提取特征)多尺度地生成proposal,然后做RoIPooling时会根据proposal的大小将它分配到不同的level去crop特征,小的proposal去low-level的层,大的proposal去high-level的层。
这样做虽然简单也蛮有效,但它不是最好的处理方式,尽管P2-P5(N2-N5)已经融合了low-level和high-level的特征,然后它们的主要特征还是以它本有的level为主 重要的特征与所在的层无关,如果小的proposal能从high-level层获取到更多的上下文语义信息和较大识别域是有利于它分类的,而大的proposal能从low-leve层获取到更好的细节是有利定位准确性的
因此,打算每个proposal从所有level的特征上做RoIPooling,然后在后面融合,融合的阶段和方式都可实验,比如分类时是两个fc,这个融合阶段可以是fuse,fc1, fc2或者fc1, fuse, fc2,融合策略可是sum也可以是max,最后证明fc1, fuse,fc2和max最好。这个改进是增加些运算负担。
FC融合:
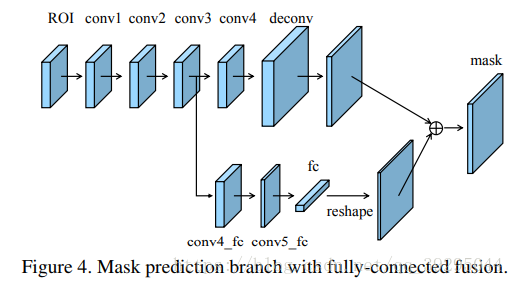
MaskRCNN中Mask分支就是个简版的fcn,fcn是全卷积网络,它根据一个局部的视野域来预测,且参数是全图共享,而全连接fc是全图视野域对位置更敏感,看得更大,这一点large kernel也间接证明了大视野域的作用。因此,这里打算多加一条用全连接层预测的支路来做mask预测,然后和fcn融合,具体做法如下图所示,至于conv4_fc接在fcn支路哪一个卷积后后面融合,,实验对比,conv3后面结果更好一点。
分割线
Deep Mask和Sharp Mask
参考连接点击
DeepMask的技巧是把分割看成是一个海量的二进制分类问题:
- 对一张图像中的每一个重叠的图像块:这个图像块包含一个物体吗?如果包含,那对于一个图像块中的每个像素:这个像素是图像块中心物体的一部分吗?用深度网络来回答每一个Yes/No的问题。
- 上层功能以相当低的空间分辨率计算,这为mask预测带来一个问题:mask能捕捉一个物体大致外形,但不能准确捕捉物体边界。
SharpMask优化DeepMask的输出,产生具有更高保真度的能精确框定物体边界的mask:
- 在DeepMask预测前向通过网络时,SharpMask反转信息在深度网络的流向,并通过使用progressively earlier
layers的特性来优化DeepMask做的预测。 - 要捕捉物体外形,你必须高度理解你正在看的是什么(DeepMask);但是要准确框出边界,你需要使用低层次的特性一直到像素级(SharpMask)
DeepMask不知道具体对象类型,尽管可以框定但不能区分物体;以及没有选择性,会为不是感兴趣的图像区域生成mask:
- 训练一个单独的深度网络来对每一个DeepMask产生的mask的物体类型进行分类(包括“无”),采用R-CNN
- 使用DeepMask作为R-CNN的第一阶段,对于RCNN的第二阶段,使用一个专门的网络架构来对每一个mask进行分类,也就是MultiPathNet,允许信息以多种路径通过网络,从而使其能够在多种图像尺寸和图像背景中挖掘信息。
分割线
CenterMask
简单而有效的无锚点的实例分割–CenterMask。
需要说明的是:CenterMask是自底而上的one-stage实例分割网络。
主要分为两个平行分支:
- 第一个为分支局部形状预测分支:从每个对象的中心点表示(类似于CenterNet中的Center)预测粗糙形(由一个粗掩模表示,该粗掩模将物体与近距离物体分开),这可以约束每个对象的局部区域并自然区分实例。
- 第二个分支预测整个图像的显著性图,实现精确分割并保留精确的空间位置。能够较好的保留物体的位置信息,实现像素级的特征对齐。
- 最后,通过将两个分支的输出相乘来构造每个实例的掩码。
不错的Center Mask的博客:CVPR2020|美团无人配送CVPR2020论文CenterMask解读
一阶段(one-stage)无锚点(anchor-free)的目标检测方法迎来了新一轮的爆发,很多优秀的one-stage目标检测网络被提出,如CenterNet[3], FCOS[4]等。不依赖预设定的anchor,直接预测bounding box所需的全部信息,如位置、框的大小、类别等,因此具有框架简单灵活,速度快等优点。于是很自然的便会想到,实例分割任务是否也能够采用这种one-stage anchor-free的思路来实现更优的速度和精度的平衡?我们的论文分析了该问题中存在的两个难点,并提出CenterMask方法予以解决。
现有的实例分割方法可大致分为两类:二阶段(two-stage)实例分割方法和一阶段(one-stage)实例分割方法。
二阶段(two-stage)实例分割方法
two-stage的实例分割遵循先检测后分割的流程,首先对全图进行目标检测得到bounding box,然后对bounding box内部的区域进行分割,得到每个物体的mask。two-stage的方法的主要代表是Mask R-CNN[1],该方法在Faster R-CNN[2]的网络上增加了一个mask分割的分支,用于对每个感兴趣区域(Region of Interest,简称ROI)进行分割。而把不同大小的ROI映射为同样尺度的mask会带来位置精度的损失,因此该方法引入了RoIAlign来恢复一定程度的位置信息。PANet[5]通过增强信息在网络中的传播来对Mask R-CNN网络进行改进。Mask Scoring R-CNN[6]通过引入对mask进行打分的模块来改善分割后mask的质量。上述two-stage的方法可以取得SOTA的效果,但是方法较为复杂且耗时,因此人们也开始积极探索更简单快速的one-stage实例分割算法。
一阶段(one-stage)实例分割方法
现有的one-stage实例分割算法可以大致分为两类:基于全局图像的方法和基于局部图像的方法。
- 基于全局的方法首先生成全局的特征图,然后利用一些操作对特征进行组合来得到每个实例的最终mask。比如,InstanceFCN[7]首先利用全卷积网络[8](FCN)得到包含物体实例相对位置信息的特征图(instance-sensitive score maps),然后利用assembling module来输出不同物体的分割结果。YOLACT[9]首先生成全局图像的多张prototype masks,然后利用针对每个实例生成的mask coefficients对prototype masks进行组合,作为每个实例的分割结果。基于全局图像的方法能够较好的保留物体的位置信息,实现像素级的特征对齐(pixel-to-pixel alignment),但是当不同物体之间存在相互遮挡(overlap)时表现较差。
- 与此相对应的,基于局部区域的方法直接基于局部的信息输出实例的分割结果。PolarMask[10] 采用轮廓表示不同的实例,通过从物体的中心点发出的射线组成的多边形来描述物体的轮廓,但是含有固定端点个数的多边形不能精准的描述物体的边缘,并且基于轮廓的方法无法很好的表示含有孔洞的物体。TensorMask[11]利用4D tensor来表示空间中不同物体的mask,并且引入了aligned representation 和 tensor bipyramid来较好的恢复物体的空间位置细节,但是这些特征对齐的操作使得整个网络比two-stage的Mask RCNN还要慢一些。
我们提出的CenterMask网络,同时包含一个全局显著图生成分支和一个局部形状预测分支,能够在实现像素级特征对齐的情况下实现不同物体实例的区分。
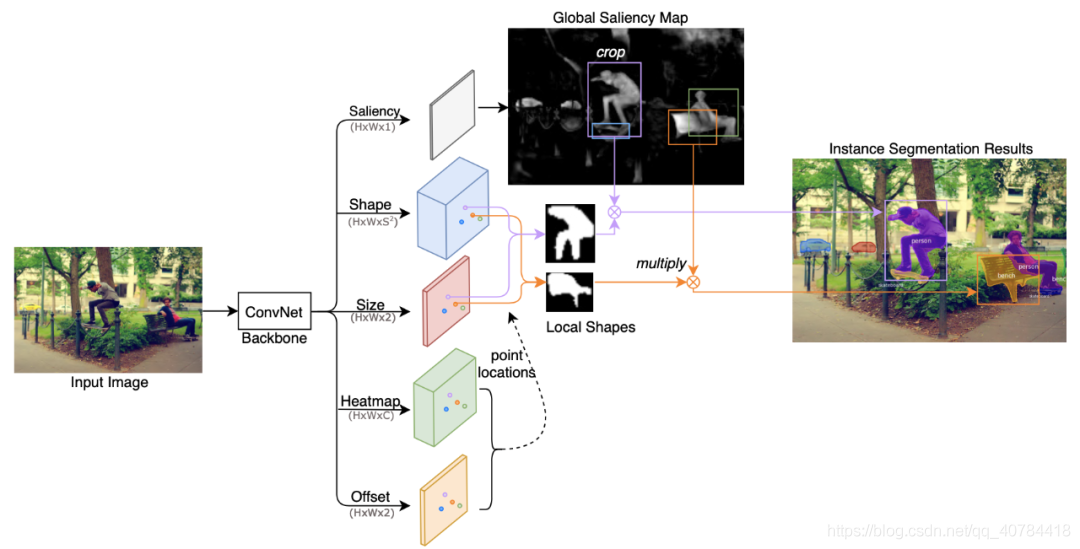
如图所示,给定一张输入图像,经过backbone网络提取特征之后,网络输出五个平行的分支。
两个分支用于中心点的预测:Heatmap和Offset分支用于预测所有中心点的位置坐标,坐标的获得遵循关键点预测的一般流程。
两个分支为局部形状(可区分实例的粗掩模):Shape和Size分支用于预测中心点处的Local Shape,为局部获得形状信息,生成区分实例的粗略的mask掩码。
一个分支实现精确分割及位置信息:Saliency分支用于预测Global Saliency Map,实现精确分割并保留精确的空间位置(不能区分实例)。
可以看到,预测的Local Shape含有粗糙但是可以区分实例的形状信息,而Global Saliency含有精细但是不能区分实例的显著性信息。最终,每个位置点处得到的Local Shape和对应位置处的Global Saliency进行乘积,以得到最终每个实例的分割结果。