牛客网 MYSQL进阶挑战 详细知识点总结(二)
目录
前言:
SQL 是结构化查询语言(Structured Query Language)的缩写,是用于管理和操作关系型数据库的标准语言。在现代的数据驱动世界中,掌握 SQL 进阶知识对于从事数据分析、数据工程、软件开发等领域的专业人士来说至关重要。SQL 进阶挑战可以帮助读者深入了解和掌握更高级的 SQL 技巧和功能。
掌握 SQL 进阶知识需要持续的学习和实践。读者应该保持耐心和坚持,在学习和实践过程中积累经验,并不断尝试解决各种数据处理问题。只有通过不断地学习和实践,才能真正掌握 SQL 进阶知识,并在实际工作中灵活运用。
一 . 索引的创建删除
1.1创建索引:
create index index_name on table_name(column_name);
如图1-1所示

图1-1
1.2查询索引:
show index from table_name ;
如图1-2所示
![]()
图1-2
1.3删除索引 :
drop index from table_name;
如图1-3所示
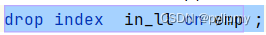
图1-3
1.4MySQL支持的索引类型及其对应的SQL语句:
B-Tree 索引:
创建索引:CREATE INDEX index_name ON table_name(column_name);
删除索引:DROP INDEX index_name ON table_name;
哈希索引:
创建索引:CREATE INDEX index_name ON table_name(column_name) USING HASH;
删除索引:DROP INDEX index_name ON table_name;
全文索引:
创建索引:CREATE FULLTEXT INDEX index_name ON table_name(column_name);
删除索引:ALTER TABLE table_name DROP INDEX index_name;
空间索引:
创建索引:CREATE SPATIAL INDEX index_name ON table_name(column_name);
删除索引:ALTER TABLE table_name DROP INDEX index_name;
前缀索引:
创建索引:CREATE INDEX index_name ON table_name(column_name(length));
删除索引:DROP INDEX index_name ON table_name;
R-Tree 索引:
创建索引:CREATE SPATIAL INDEX index_name ON table_name(column_name) USING RTREE;
删除索引:ALTER TABLE table_name DROP INDEX index_name;
Bitmap 索引:
MySQL不直接支持Bitmap索引,但可以通过使用位图索引工具或库来实现。
Adaptive Hash 索引:
Adaptive Hash索引在MySQL中是自动创建和管理的,无需手动创建或删除。
Clustered 索引:
创建索引:ALTER TABLE table_name ADD PRIMARY KEY (column_name);
删除索引:ALTER TABLE table_name DROP PRIMARY KEY;
需要注意的是,具体的创建和删除索引的语句可能会因为表名、索引名和列名等具体情况而有所变化。请根据实际情况进行调整。
二 . 聚合函数
2.1基本聚合函数:
2.1.1count:
计算某列或某个表中的行数。
统计某表中的记录数量
如图2-1所示

图2-1
2.1.2 sum:
计算某列或某个表中数值列的总和。
计算某列中的数值总和
如图2-2所示
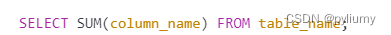
图2-2
2.1.3 avg:
计算某列或某个表中数值列的平均值。
计算某列中的数值平均值
如图2-3所示

图2-3
2.1.4 max:
找出某列或某个表中数值列的最大值。
找出某列中的最大值
如图2-4所示

图2-4
2.1.5 min:
找出某列或某个表中数值列的最小值。
找出某列中的最小值
如图2-5所示

图2-5
2.2分组聚合函数:
2.2.1group by :
按照一个或多个列对结果进行分组。
按照某列进行分组,并计算每个分组内的记录数量
如图2-6所示

图2-6
2.2.2 having:
对分组后的结果进行条件过滤。
筛选出分组后的结果中满足条件的分组
如图2-7所示
![]()
如图2-7所示
2.3 过滤聚合函数:
2.3.1 distinct :
返回唯一不重复的结果。
查询某列中的唯一不重复的值
如图2-8所示
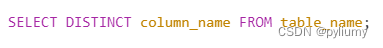
图2-8
2.3.2 where :
对查询结果进行条件过滤。
根据条件筛选查询结果
如图2-9所示

图2-9
三.分组查询
3.1group by
MySQL的分组查询是一种用于对数据进行分组统计的功能,它可以根据指定的列对数据进行分组,并对每个分组应用聚合函数进行计算。其原理如下:
3.1.1.根据 GROUP BY 子句中指定的列,将数据按照相同的值进行分组。
3.1.2.对每个分组应用聚合函数,如 COUNT、SUM、AVG 等,计算指定列上的统计结果。
3.1.3.返回每个分组的统计结果作为查询结果。
具体应用如图3-1

图3-1
在这个示例中,我们从 employees 表中按照 department 列进行分组,然后使用 COUNT 函数统计每个部门的员工数量,并使用 AVG 函数计算每个部门的平均工资。最后,我们将分组的结果返回。
需要注意的是,在分组查询中,除了被分组的列外,SELECT 子句中的列可以是聚合函数、分组的列或其他非聚合列。如果选择的列没有被分组,那么它们将被隐式地应用到所有分组上,并返回每个分组的唯一值。
通过分组查询,我们可以轻松地对数据进行分组统计,从而得到更有用的信息和洞察。
致谢:
非常感谢您阅读我们的博客!我们致力于提供有用和有趣的信息,希望能够为您带来帮助和启发。如果您有任何问题、建议或想了解特定主题,请随时告诉我们。您的反馈对我们非常重要,我们将继续努力提供高质量的内容。
如果您喜欢我们的博客,请考虑订阅我们的更新,这样您就不会错过任何新的文章和信息。同时,欢迎您分享我们的博客给更多的朋友和同事,让更多人受益。
再次感谢您的支持和关注!如果您有任何想法或需求,请随时与我们联系。祝您生活愉快,学习进步!