ViLT视觉文本多模态
内容来自b站论文精讲:
https://www.bilibili.com/video/BV14r4y1j74y?vd_source=aaa7d9b5dd88818076af6aa4b9ae0d74
一.Introduction
为了输入VLP模型,图像像素(变成语义性的,离散性的特征)最初需要与语言标记一起以密集形式嵌入。自从Krizhevsky等人的开创性工作以来。(2012),深度卷积网络被认为是这一视觉嵌入步骤的关键。大多数VLP模型采用在视觉基因组数据集(Krishna et al.,2017)上预先训练的对象检测器,该数据集注释有1,600个对象类和400个属性类,如Anderson et al.(2018).
要获得语义离散特征:之前选择用目标检测器,原因(1)天然的离散化过程,一个个bounding box,明确的语义信息;(2)下游任务都跟物体有非常强的依赖性,检测到物体对任务的完成很关键。所以选择目标检测系统作为多模态的一部分非常合理。
之前工作的缺陷和不足:
目前VLP模型大多数用了预训练好的目标检测器,这个目标检测器是在visual genome dataset(1600个目标类别+400个属性类别)上面预训练的。选用该数据集的原因是:类别多,能够更好地和文本这边匹配起来,文本能够用单词来表示的类别是极其丰富的。为了比较的公平性,大家都用keishna2017的目标检测器。
但是用目标检测器去抽特征,太贵,一些工作尝试去降低计算量,比如:pixcel bert,它用了在imagenet上预训练好的残差网络,直接把残差网络得到的特征图当成是一个离散的序列。这样就只有backbone,没有目标检测相关的操作了,速度变快不少。
作者认为,用目标检测器和残差网络抽特征都还是太贵了。现在的工作主要还是关注视觉编码器的提升,从而能提升最后的性能。学术界优先考虑的性能,性能刷不动了才是速度和效率。其实在训练的过程中,大家可以提前把目标检测的特征都抽好,然后存在本地的硬盘上,训练的时候直接用就行。所以抽特征的过程是在线下完成的,早就已经把特征抽好存在硬盘上了,训练是很轻量的。但是真实世界实际应用的时候,数据都是实时生成的新数据,对新数据也要抽特征,推理的时候时间无法忽略。
因此本文希望获得轻量化更简单的图像特征抽取的方法。基于vit这篇论文的想法,vit在多模态领域里的应用:把图像打成patch,然后用一个简单的linuear projection层 把patch变成embedding的方式,从而取消掉图像特征抽取的过程。
用patch embedding去替换之前繁琐的抽特征的过程。
模型
vilt模型很简单,图1,看出怎么做的。
1.目标检测方式抽特征
先特征提取,再获得一个个物体;文本也获得序列。文本和图像的两个序列,直接连接在一起变成一个序列,再扔到一个模型中训练;本文序列扔到一个模型,图片序列扔到另一个模型,两个单独模态的模型在某个时间点上再做融合,成为two stream,两通道结构。
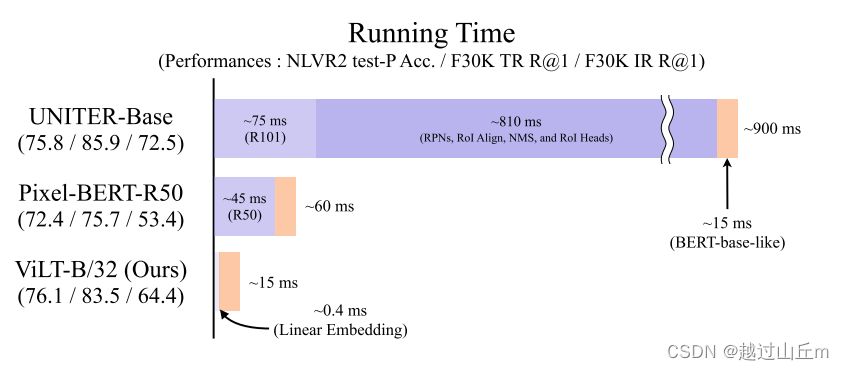
缺点:太贵了,backbone75m,后面目标检测专有的nms等占到8210ms。
改进:把目标检测的操作去掉。
2.网格特征
图片扔到卷积神经网络,最后一层比如7*7拉直成序列,好处是直接用卷积神经网络的特征图就够了,不需要用目标检测相关的东西。运行时间锐减到45ms.
缺点:速度还是不够。
3.本文
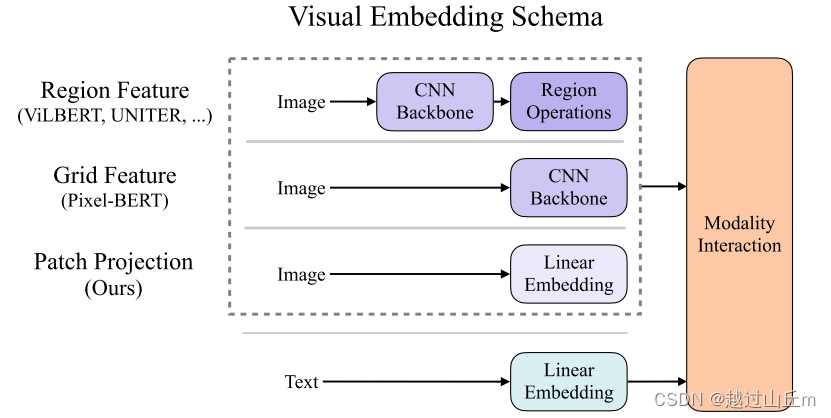
本文认为vit的patch embedding工作的很好。其中,vit论文中作者也对比过,前面只用一个简单的linear projection层和使用resnet50去抽取图像像素级别特征,效果差不多,甚至可学习的linear projection层表现的更好。因此本文中直接照搬,把cnn backbone换成linear embedding层,这个时候图像和文本完全对应起来,图像打成patch通过一个linear embedding层获得图像初始的token,文本通过linear embedding得到word token,然后都可以直接扔给transformer。
从时间上看,patch linear embedding非常快速,只需要0.4ms,基本不花什么时间。性能上,在NLVR2 test-P Acc./F30K TR R@1/F30K IR R@1这3个数据集上做了一些测试,看出还是第一种基于目标检测的方法达到的效果最好,网格的方法性能下降明显,vilt做了比较好的取舍,速度快,性能下降少。
vilt做的贡献:
(1)目前最简单的做vision-and-language的模型,因为只用transformer做了模态间的融合之外,没有再用其他的模型了,而不需要残差网络甚至一些额外的目标检测的网络结构在里面。这个设计带来了非常显著的运行时间和参数量的减少。
(2)减少计算复杂度的同时,保证了性能能不掉。在不是用区域特征或者这种残差网络特征(原文:deep convolutional visiual embedders)的情况下,达到和之前差不多的效果。算是第一个做到的给工作。
(3)训练的时候用到了更多的数据增强的方式,文本中用到了整个词mask掉的方式,图片这边尝试使用了redmog(?)。这两种数据增强的方式,之前在多模态领域都没有被用过。因为多模态学习总要考虑图像文本对之间匹配的问题,不论给图像还是文本这边做了增强,往往可能导致图像文本对就不匹配了,不是正确的对了。之前的多模态学习就没有考虑用过强的数据增强的方式,但是vilt巧妙地利用了数据增强的方式,稍微改了一带你,然后发现效果非常好。即使图像文本对有很多,用了数据增强之后,效果还是会更好。(对于当时的多模态领域也是第一次)
总体而言,vilt提出了一个非常简单而且强大的基线模型,得出了很多很有意思的结论、很多对训练有帮助的小技巧,然后再加上transformer在视觉领域的大杀四方,所以在多模态领域新工作也如雨后春笋一般冒出来了。
二、背景知识

写的像综述论文,现在vlp大概可以分为哪几类,当有了文本和图像的token之后怎么去做图像间的融合,因为文本抽特征都是一样的,就把图像怎么抽特征进行单独介绍(从一开始的目标检测的区域特征,到使用残差网络最终的特征图,到最新的vit出来,用一个简单的linear projection layer,完成对视觉特征的抽取)。
2.1 领域中对模型的划分
为了介绍好vilt突出其优势,煞费苦心。
先做了一个总结,对现在所有的vlp的模型做了一个分类,根据两点(1)怎么从各个模态上先抽一些特征、先做一些预处理:图像和文本表达力度是否平衡:参数量、计算量;(理论上应该差不多,不应该像现在大多数方法一样视觉比文本贵很多)(2)这两个模态怎么去融合。
根据这两点,把所有方法分成了四个类。
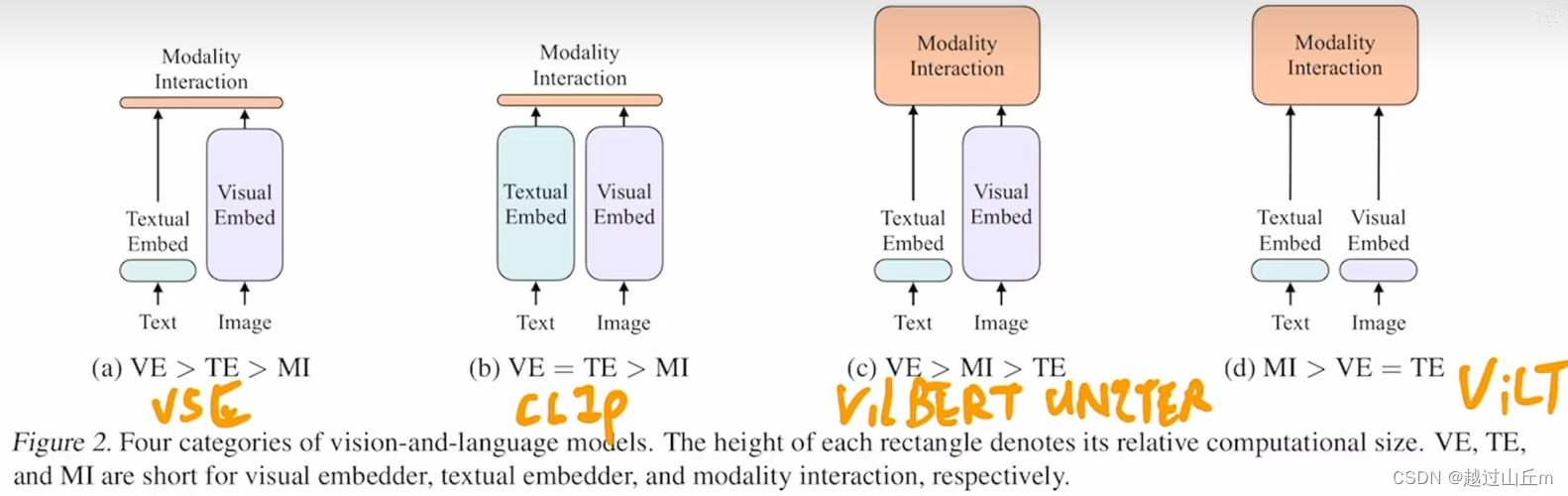
ve:怎么抽图像特征;
te:怎么抽文本特征;
mi:两个模态怎么做融合。
(a)较早的给弘佐,vse系列的工作,视觉端贵,文本轻量,融合轻量,简单点乘或者非常浅层的神经网络。
(b)代表工作clip模型,非常好用,主要特点图像文本表达力度一样,计算量上等价,模态融合也轻量,直接点乘。所以说clip这个模型,适合做抽特征或者retrieve的任务,但是去做别的多模态的下游分类任务,如vqa、visual reasoning,它的效果略逊,因为这些任务需要把抽到的两个特征好好地融合一下才能知道二者之间的对应关系,一个不可学习的简单的点乘是没办法做到更深层次的分析的。
(c)前两年的工作基本都是如此,文本端非常轻量、图像端基本用的目标检测的系统,不仅抽特征贵,后面模态融合的时候也非常贵,后面又跟了transformer。所以相当于有两个模型,前面有个visual backbone,后面还有一个大的transformer。但是,性能确实不错,各个多模态的下游任务性能都刷的非常高。
(d)
作者这里找准了机会,通过分析这些工作之后发现,模态融合的模型一定要比较大,好好做模态融合最后的效果才能好,跟之前抽的特征关系不太大。再加上vision transformer的出现,patch embedding layerr直接就工作的很好,所以vilt直接把patch embedding拿过来,使得视觉抽特征也很轻量,变成了mi>ve=te。
(对现有领域里比较好的分类,非常有利于加强对这个领域的理解,而且很有可能在做完总结之后,也就知道当前领域的痛点在哪里了,并且可能会有很多的新的想法,因此初入一个领域,不妨尝试去写这个领域的综述论文,中不中稿、中在哪里都可以,加深对领域的认知,提升逻辑性和写作能力)
2.2 之前的方法怎么做模态的融合
1.single-stream approaches
只用一个模型处理两个输入,两个序列直接concate成一个序列,它们直接怎么交互不管,transformer自己去学就好。
2.dual-stream approaches
有两个模型,先各自对各自的输入做一些处理,充分挖掘单独模态里包含的信息,然后在后面的某一个时间点再去做融合,比如说加一些transformer layyer。
整体来看,两个方面工作多,性能差不多。但是dual-stream还是参数更多更贵。作者还是选择了singal-stream的方法,抽完图像和文本的特征之后,直接concate到一起。
2.3 融合之前特征应该怎么抽取
文本中都用的相同的轻量的embedder- tokenizer from pre-trained BERT。因此介绍视觉怎么抽特征。
- 区域特征region feature
之前的方法怎么把目标检测系统嵌入到多模态学习里面 ,大概分为3步:
(1)给定一个图像之后,先通过一个backbone,比如resnet101去抽特征;
(2)有一个rpn网络抽一些roi出来,然后再做一次nms,把roi降到一个固定的数量,这个数量就是序列的长度;
(3)得到这些bound ing box之后,通过roi head就能得到一些一维的向量,也就是region feature。
虽然听起来合理,连续图片变成一些离散的bound ing box,每个bounding box都有对应的特征,这就跟文本那边匹配起来了,但是这整个过过程非常的贵,怎么都比如过只用一个cnn的backbone或者只用一层的patch embedding(However lightweight,object detectors are less likely tobe faster than the backbone or a single-layer convolution)。 - grid feature
怎么用一个预训练好的cnn直接把它的特征图拿出来,就得到grid feature。比region feature便宜一些,但是还是比较贵,并且性能也非常不好,有的任务下降十几个点,大家无法接受。
因此自然而然引出了本文的方法: - patch projection
借鉴vit的patch embedding layer,直接用一层patch projection把图像特征抽出来,比用卷积网络的backbone甚至目标检测系统快很多很多,而且效果还能持平。这个框架非常有吸引力,大家会在这个框架下做进一步的修改。
三、模型
结构很简单:就是一个transformer,前面是一个linear embedding层,很多概念技巧都是之前transformer那边有的,所以没有太多可以介绍的新的东西。
模型的训练以及目标函数:也和之前的差不多,就是用了image text matching loss和mask language model loss。
那么本文的方法创新点在哪儿:
(1)换成一层的patch embedding layer;
(2)训练的过程中有一些非常有用的技巧,比如说,nlp中常用的技巧whole word masking,整个单词都mask掉,该方法在很多论文中都证实了有效;图像这边用了很强的数据增强,用来randon markement,效果提升非常多。(之后的很多的工作,也和vilt一样,也用该方法来数据增强l)
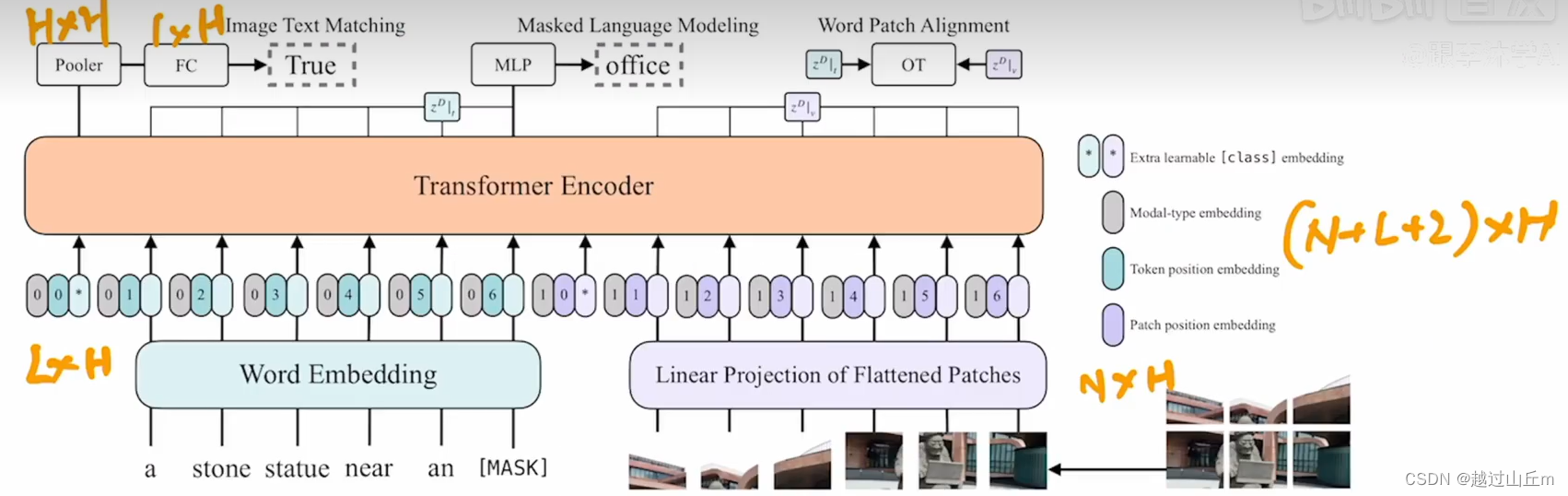
总之,只有一个模型的方法。
并不容易跟进,非pytorch上手难,吃卡。
lbufff不那么吃卡了。
消融(到底哪一块最好):
训练时间
结论 未来工作
极小化
(未完待续)