Python大数据实践:selenium爬取京东评论数据
准备工作
selenium安装
Selenium是广泛使用的模拟浏览器运行的库,用于Web应用程序测试。 Selenium测试直接运行在浏览器中,就像真正的用户在操作一样,并且支持大多数现代 Web 浏览器。
#终端pip安装
pip install selenium
#清华镜像安装
pip install selenium -i https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/win-64/
安装Chrome driver
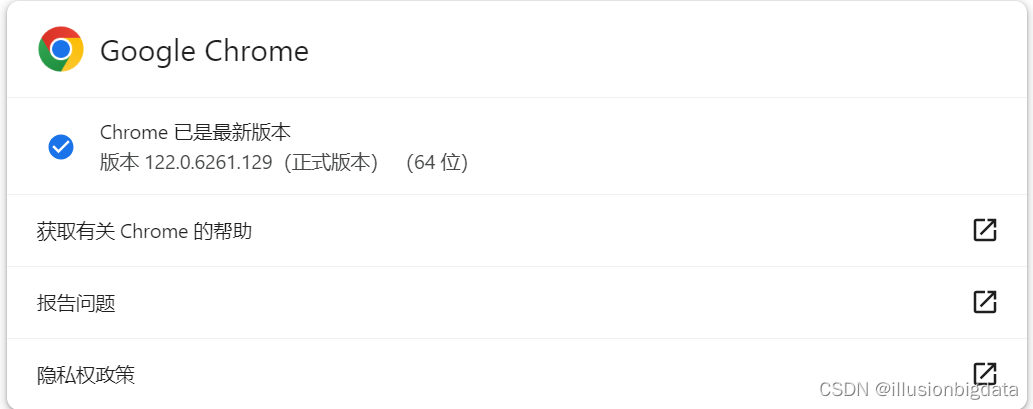
查看Google版本,并下载对应版本的驱动
下载路径
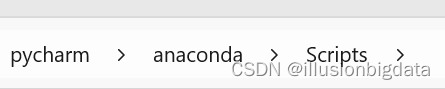
安装在anaconda的Scripts文件夹中
测试
from selenium import webdriver
# 初始化WebDriver
browser = webdriver.Chrome()如果弹出Chrome浏览器,则说明安装成功

爬虫
示例:爬取【AppleiPhone 13】Apple/苹果 iPhone 13 (A2634)128GB 绿色 支持移动联通电信5G 双卡双待手机【行情 报价 价格 评测】-京东
先导入所用的包,这样一步一步跟着做不会出错
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
import time初始化并访问
# 初始化WebDriver
browser = webdriver.Chrome()
# 访问商品页面
browser.get('https://item.jd.com/100034710036.html')
# 等待页面加载完成
time.sleep(5)登录
QQ、微信登录或扫码登陆均可
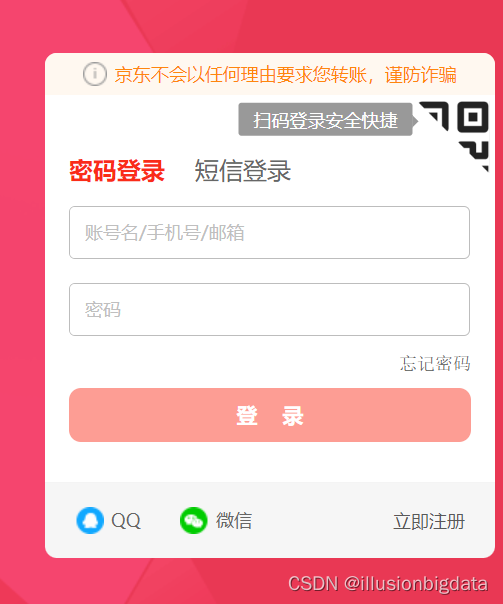
正常登录后的界面如下
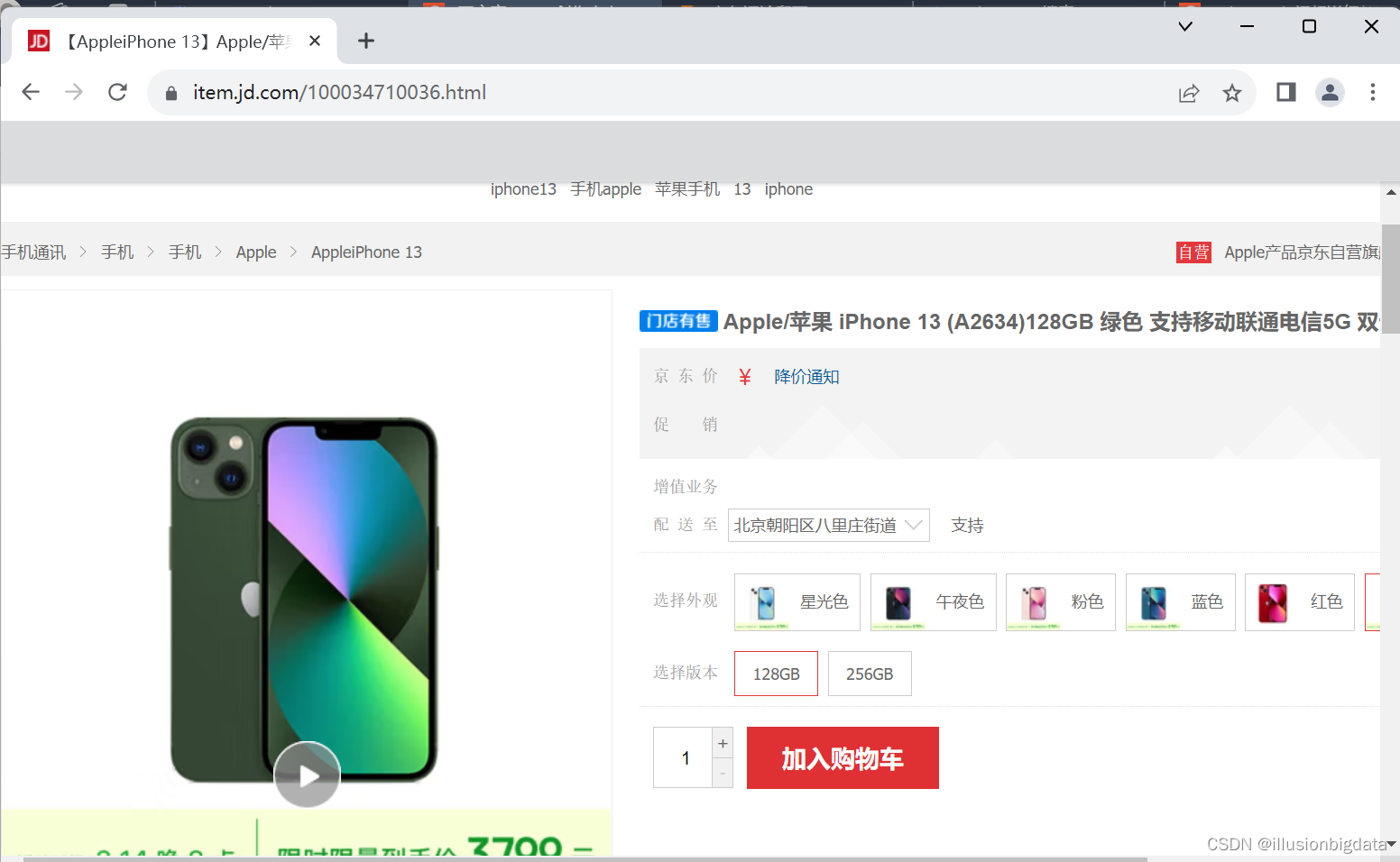 控制点击商品评价按钮
控制点击商品评价按钮
# 点击“商品评价”按钮
try:
# 等待“商品评价”按钮可点击
WebDriverWait(browser, 10).until(
EC.element_to_be_clickable((By.XPATH, '//*[@id="detail"]/div[1]/ul/li[5]'))
).click()
except Exception as e:
print(f"Error clicking the '商品评价' button: {e}")
browser.quit()
exit()正则表达式要通过F12检查页面源码去看!!!
爬取评论数据
# 设置要爬取的页数
num_pages_to_scrape = 5
# 循环爬取多页评论
for page_num in range(1, num_pages_to_scrape + 1):
print(f"Scraping page {page_num}...")
# 等待评论加载完成
try:
WebDriverWait(browser, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '.comment-item .comment-con'))
)
except Exception as e:
print(f"Error waiting for comments to load on page {page_num}: {e}")
break
# 获取页面源码
html = browser.page_source
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(html, 'html.parser')
# 提取评论数据
comments = soup.select('.comment-item .comment-con')
# 检查是否有评论
if comments:
for comment in comments:
# 提取评论内容
content = comment.get_text(separator='\n')
print(content)
else:
print("No comments found on page {page_num}.")
检查是否有下一页(不是必要操作)
因为测试时报错找不到下一页,因此添加检查是否有下一页的操作。如果上述操作没有错误,就可以不加。
# 检查是否还有下一页
if page_num < num_pages_to_scrape:
# 点击“下一页”按钮
try:
# 等待“下一页”按钮可点击
next_page_button = WebDriverWait(browser, 10).until(
EC.element_to_be_clickable((By.CLASS_NAME, 'ui-pager-next'))
)
# 点击下一页按钮
next_page_button.click()
# 等待Ajax请求完成
WebDriverWait(browser, 10).until(
EC.invisibility_of_element_located((By.CLASS_NAME, 'loading-indicator'))
)
except Exception as e:
print(f"Error clicking the '下一页' button or waiting for Ajax request on page {page_num}: {e}")
break结果
爬取结果如下,每爬一页都会显示是第几页
