C++ 逻辑回归模型求解 (基于Eigen)
1. 目标函数:sigmoid函数
f_wb=1/[1+exp(-z)]
z=wx+b,w和x是n维向量
/**
* @author @还下着雨ZG
* @brief sigmoid函数,用于实现逻辑回归
* @param[in] z
* @return 1/(1+exp(-z))
*/
double sigmoid(const double &z){
return 1/(1+exp(-z));
}
2. 损失函数:
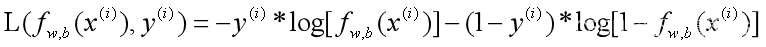
3. 代价函数:
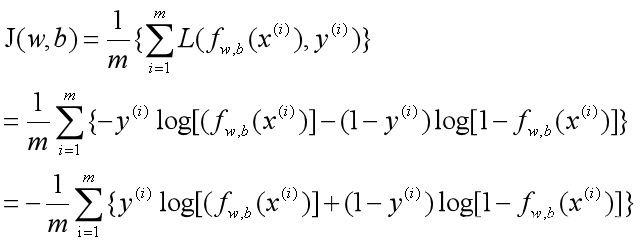
计算模型的代价:
/**
* @author @还下着雨ZG
* @brief 计算逻辑回归模型的代价cost
* @param[in] X
* @param[in] y
* @param[in] w_in
* @param[in] b_in
* @return cost
*/
double compute_cost(MatrixXd X,VectorXi &y,VectorXd &w_in,double b_in){
int m=X.rows();
double cost=0;
for(int i=0;i<m;++i){
double z=w_in.dot(X.row(i))+b_in;
double f_wb=sigmoid(z);
cost+=-y[i]*log(f_wb)-(1-y[i])*log(1-f_wb);
}
return cost/m;
}
4. 梯度下降法优化模型得到最佳参数
(1)计算代价函数的梯度:
/**
* @author @还下着雨ZG
* @brief 计算逻辑回归模型的梯度
* @param[in] X
* @param[in] y
* @param[in] w_in
* @param[in] b_in
* @return pair(diff_w,diff_b) 可以携带两组参数
*/
std::pair<VectorXd,double> compute_gradient(MatrixXd &X,VectorXi &y,
VectorXd &w_in,double &b_in){
int m=X.rows();int n=X.cols();
VectorXd diff_w=VectorXd::Zero(n);
VectorXd w=w_in;double b=b_in;
double diff_b;
double f_wb=0.0,z=0.0;
for(int i=0;i<m;++i){
z=w.dot(X.row(i))+b;
f_wb=sigmoid(z);
double error=f_wb-y[i];
for(int j=0;j<n;j++) diff_w[j]+=error*X(i,j);
diff_b+=error;
}
diff_w=diff_w/m;diff_b=diff_b/m;
return std::make_pair(diff_w,diff_b);
}
(2) 梯度下降法求解参数:
/**
* @brief 梯度下降求解目标函数sigmoid的最佳参数
* @param[in] X
* @param[in] y
* @param[in] w_init
* @param[in] b_init
* @param[in] learning_rate
* @param[in] iterations 迭代次数
* @return w_out,b_out
*/
std::pair<VectorXd,double> gradient_descent(MatrixXd &X,VectorXi &y,VectorXd &w_init,
double &b_init,double &alpha,int &iterations){
int m=X.rows();int n=X.cols();
VectorXd w(w_init);double b=b_init;
VectorXd diff_w(n);double diff_b=0.0;
for(int i=0;i<iterations;++i){
auto gradient_res=compute_gradient(X,y,w,b);
diff_w=gradient_res.first;diff_b=gradient_res.second;
w=w-alpha*diff_w;
b=b-alpha*diff_b;
}
return std::make_pair(w,b);
}
可直接运行代码实例:
#include <iostream>
#include <Eigen/Dense>
#include <string>
using namespace Eigen;
/**
* @author @还下着雨ZG
* @brief sigmoid函数,用于实现逻辑回归
* @param[in] z
* @return 1/(1+exp(-z))
*/
double sigmoid(const double &z){
return 1/(1+exp(-z));
}
/**
* @author @还下着雨ZG
* @brief 计算逻辑回归模型的代价cost
* @param[in] X
* @param[in] y
* @param[in] w_in
* @param[in] b_in
* @return cost
*/
double compute_cost(MatrixXd X,VectorXi &y,VectorXd &w_in,double b_in){
int m=X.rows();
double cost=0;
for(int i=0;i<m;++i){
double z=w_in.dot(X.row(i))+b_in;
double f_wb=sigmoid(z);
cost+=-y[i]*log(f_wb)-(1-y[i])*log(1-f_wb);
}
return cost/m;
}
/**
* @author @还下着雨ZG
* @brief 计算逻辑回归模型的梯度
* @param[in] X
* @param[in] y
* @param[in] w_in
* @param[in] b_in
* @return pair(diff_w,diff_b) 可以携带两组参数
*/
std::pair<VectorXd,double> compute_gradient(MatrixXd &X,VectorXi &y,
VectorXd &w_in,double &b_in){
int m=X.rows();int n=X.cols();
VectorXd diff_w=VectorXd::Zero(n);
VectorXd w=w_in;double b=b_in;
double diff_b;
double f_wb=0.0,z=0.0;
for(int i=0;i<m;++i){
z=w.dot(X.row(i))+b;
f_wb=sigmoid(z);
double error=f_wb-y[i];
for(int j=0;j<n;j++) diff_w[j]+=error*X(i,j);
diff_b+=error;
}
diff_w=diff_w/m;diff_b=diff_b/m;
return std::make_pair(diff_w,diff_b);
}
/**
* @brief 梯度下降求解目标函数sigmoid的最佳参数
* @param[in] X
* @param[in] y
* @param[in] w_init
* @param[in] b_init
* @param[in] learning_rate
* @param[in] iterations 迭代次数
* @return w_out,b_out
*/
std::pair<VectorXd,double> gradient_descent(MatrixXd &X,VectorXi &y,VectorXd &w_init,
double &b_init,double &alpha,int &iterations){
int m=X.rows();int n=X.cols();
VectorXd w(w_init);double b=b_init;
VectorXd diff_w(n);double diff_b=0.0;
for(int i=0;i<iterations;++i){
auto gradient_res=compute_gradient(X,y,w,b);
diff_w=gradient_res.first;diff_b=gradient_res.second;
w=w-alpha*diff_w;
b=b-alpha*diff_b;
}
return std::make_pair(w,b);
}
int main(){
using std::cout;using std::endl;using std::string;
MatrixXd X_train{{0.5, 1.5}, {1,1}, {1.5, 0.5}, {3, 0.5}, {2, 2}, {1, 2.5}};
int m=X_train.rows();
int n=X_train.cols();
VectorXi y_train(m);
y_train<<0, 0, 0, 1, 1, 1;
VectorXd w_init(n);w_init<<2.0,3.0;
double b_init=1.0;
double learning_rate=0.1;
int iterations=10000;
auto res=gradient_descent(X_train,y_train,w_init,b_init,learning_rate,iterations);
VectorXd w=res.first;
double b=res.second;
cout<<w<<endl;
cout<<b<<endl;
return 0;
}