【OpenCV实战】车牌识别(OCR)中字符分割的两种方法Python实现(总结)
【OpenCV实战】车牌识别(OCR)中字符分割的两种方法Python实现
车牌识别是一个经典项目了,车牌的字符分割是很重要的一部分,字符分割的思想在其他项目中同样有很重要的作用。有必要针对字符分割的思路和实现过程做一个记录。
本篇博客的对象是

目的是实现车牌的字符分割。
总的来说
车牌识别的字符分割可以有两种思路:
(1)基于连通域(边缘特征)的字符分割:通过形态学处理是的各个字符成为一个整体(主要针对汉字),通过边缘检测获取每一个字符的轮廓,即可实现字符分割。
(2)基于像素直方图的字符分割:对图片进行二值化处理,统计水平方向和竖直方向上各行各列的黑色像素的个数,根据像素的特点确定分割位置,完成字符分割。
1、基于连通域(边缘特征)的字符分割
思路比较简单,根据轮廓特征分割。话不多说,直接上代码
import cv2
from matplotlib import pyplot as plt
img_ = cv2.imread('Resources/test1.png') # 读取图片
img_gray = cv2.cvtColor(img_, cv2.COLOR_BGR2GRAY) # 转换了灰度化
# 形态学操作
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (2, 2))
image = cv2.dilate(image, kernel)
# 查找轮廓
contours, hierarchy = cv2.findContours(image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
words = []
word_images = []
for item in contours:
word = []
rect = cv2.boundingRect(item)
x = rect[0]
y = rect[1]
weight = rect[2]
height = rect[3]
word.append(x)
word.append(y)
word.append(weight)
word.append(height)
words.append(word)
words = sorted(words,key=lambda s:s[0],reverse=False)
i = 0
for word in words:
# 根据轮廓的外接矩形筛选轮廓
if (word[3] > (word[2] * 1)) and (word[3] < (word[2] * 3)) and (word[2] > 10):
i = i+1
splite_image = image_[word[1]:word[1] + word[3], word[0]:word[0] + word[2]]
splite_image = cv2.resize(splite_image,(25,40))
word_images.append(splite_image)
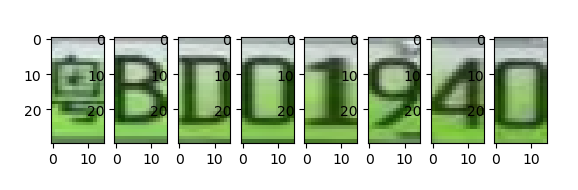
for i,j in enumerate(word_images):
plt.subplot(1,7,i+1)
plt.imshow(word_images[i],cmap='gray')
plt.show()
代码效果:

2、基于像素直方图的字符分割
思路:
(1)对图像进行二值化操作,得到效果图如图

(2)水平方向:统计每一行黑色像素数量n,并记录。可以根据每一行黑色像素的数目来确定分割的起始和终止;由图可知,当 n减小到一定阈值时,为字符的边缘;
(3)竖直方向:同理,统计每一列的黑色像素数量v,并记录。可以可以根据每一列黑色像素的数目的变化来确定分割的起始和终止。
这里提供两套代码,可以根据自己的选择使用,思路是一致的。
2.1代码一:
import cv2
import numpy as np
img_ = cv2.imread('Resources/test1.png') # 读取图片
img = cv2.cvtColor(img_, cv2.COLOR_BGR2GRAY) # 转换了灰度化
# 图像阈值化操作——获得二值化图
ret, img_thre = cv2.threshold(img, 100, 255, cv2.THRESH_BINARY_INV)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (2, 2)) # 形态学处理:定义矩形结构
closed = cv2.dilate(img_thre, kernel, iterations=1) # 闭运算:迭代5次
height, width = closed.shape[:2]
# 储存每一列的黑色像素数
v = [0] * width
# 储存每一行的黑色像素数
z = [0] * height
hfg = [[0 for col in range(2)] for row in range(height)]
lfg = [[0 for col in range(2)] for row in range(width)]
box = [0,0,0,0]
######水平投影 #统计每一行的黑点数,行分割#######
a = 0
emptyImage1 = np.zeros((height, width, 3), np.uint8)
for y in range(0, height):
for x in range(0, width):
if closed[y, x] == 0:
a = a + 1
else:
continue
z[y] = a
a = 0
# 绘制水平投影图
l = len(z)
for y in range(0, height):
for x in range(0, z[y]):
b = (255, 255, 255)
emptyImage1[y, x] = b
#根据水平投影值选定行分割点
inline = 1
start = 0
j = 0
# print(height,width)
# print(z)
for i in range(0,height):
# inline 为起始位置标识,0.95 * width可自行调节,为判断字符位置的条件
if inline == 1 and z[i] < 0.95 * width: #从空白区进入文字区
start = i #记录起始行分割点
#print i
inline = 0
# i - start > 3字符分割长度不小于3,inline为分割终止位置标识,0.95 * width可自行调节,为判断字符位置的条件
elif (i - start > 3) and z[i] >= 0.95 * width and inline == 0 : #从文字区进入空白区
inline = 1
hfg[j][0] = start - 2 #保存行分割位置
hfg[j][1] = i + 2
j = j + 1
####################### 至此完成行的分割 #################
#####对每一行垂直投影、分割#####
a = 0
for p in range(0, j):
# 垂直投影 #统计每一列的黑点数
for x in range(0, width):
for y in range(hfg[p][0], hfg[p][1]):
cp1 = closed[y,x]
if cp1 == 0:
a = a + 1
else :
continue
v[x] = a #保存每一列像素值
a = 0
print(v)
# 创建空白图片,绘制垂直投影图
l = len(v)
emptyImage = np.zeros((height, width, 3), np.uint8)
for x in range(0, width):
for y in range(0, v[x]):
b = (255, 255, 255)
emptyImage[y, x] = b
#垂直分割点
incol = 1
start1 = 0
j1 = 0
z1 = hfg[p][0]
z2 = hfg[p][1]
word = []
for i1 in range(0,width):
if incol == 1 and v[i1] <= 34 : #从空白区进入文字区
start1 = i1 #记录起始列分割点
incol = 0
elif (i1 - start1 > 3) and v[i1] > 34 and incol == 0 : #从文字区进入空白区
incol = 1
lfg[j1][0] = start1 - 2 #保存列分割位置
lfg[j1][1] = i1 + 2
l1 = start1 - 2
l2 = i1 + 2
j1 = j1 + 1
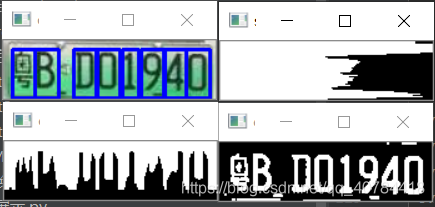
cv2.rectangle(img_, (l1, z1), (l2, z2), (255,0,0), 2)
cv2.imshow('original_img', img_)
cv2.imshow('erode', closed)
cv2.imshow('chuizhi', emptyImage)
cv2.imshow('shuipin', emptyImage1)
cv2.waitKey(0)
cv2.destroyAllWindows()
代码效果:
2.2代码二:
import cv2
from matplotlib import pyplot as plt
## 根据每行和每列的黑色和白色像素数进行图片分割。
# 1、读取图像,并把图像转换为灰度图像并显示
img_ = cv2.imread('Resources/test1.png') # 读取图片
img_gray = cv2.cvtColor(img_, cv2.COLOR_BGR2GRAY) # 转换了灰度化
# cv2.imshow('gray', img_gray) # 显示图片
# cv2.waitKey(0)
# 2、将灰度图像二值化,设定阈值是100
ret, img_thre = cv2.threshold(img_gray, 100, 255, cv2.THRESH_BINARY_INV)
# 4、分割字符
white = [] # 记录每一列的白色像素总和
black = [] # ..........黑色.......
height = img_thre.shape[0]
width = img_thre.shape[1]
white_max = 0
black_max = 0
# 计算每一列的黑白色像素总和
for i in range(width):
s = 0 # 这一列白色总数
t = 0 # 这一列黑色总数
for j in range(height):
if img_thre[j][i] == 255:
s += 1
if img_thre[j][i] == 0:
t += 1
white_max = max(white_max, s)
black_max = max(black_max, t)
white.append(s)
black.append(t)
# print(s)
# print(t)
arg = False # False表示白底黑字;True表示黑底白字
if black_max > white_max:
arg = True
# 分割图像
def find_end(start_):
end_ = start_ + 1
for m in range(start_ + 1, width - 1):
if (black[m] if arg else white[m]) > (0.95 * black_max if arg else 0.95 * white_max): # 0.95这个参数请多调整,对应下面的0.05(针对像素分布调节)
end_ = m
break
return end_
n = 1
start = 1
end = 2
word = []
while n < width - 2:
n += 1
if (white[n] if arg else black[n]) > (0.05 * white_max if arg else 0.05 * black_max):
# 上面这些判断用来辨别是白底黑字还是黑底白字
# 0.05这个参数请多调整,对应上面的0.95
start = n
end = find_end(start)
n = end
if end - start > 5:
cj = img_[1:height, start:end]
cj = cv2.resize(cj, (15, 30))
word.append(cj)
print(len(word))
for i,j in enumerate(word):
plt.subplot(1,8,i+1)
plt.imshow(word[i],cmap='gray')
plt.show()
代码效果: