NEMU PA1实验思路
NEMU PA1实验思路
版权归zzy所有,不许外传!
本文主要是提供PA1思路,为了避免踩了一堆坑而浪费时间。若想copy代码请移步他处,本文仅供学习交流用,谢谢!
阅读前请确保仔细阅读了PA1实验指导书的有关内容!
必做任务1 实现正确的寄存器结构体
需要了解结构体和联合体的概念,保证gpr[i]对应第i个寄存器即可。
NEMU/nemu/include/cpu/reg.h修改如下
typedef struct {
union {
union {
uint32_t _32;
uint16_t _16;
uint8_t _8[2];
} gpr[8];
struct {
uint32_t eax, ecx, edx, ebx, esp, ebp, esi, edi;
};
};
swaddr_t eip;
} CPU_state;
必做任务 2:实现单步执行、打印寄存器、扫描内存
首先模仿给的几个指令把这三个指令填入cmd_table中,关于args参数转成int的方法,手册中有写。注意有些后面需要参数的指令需要判断参数是否输入完整。
单步执行si
阅读cmd_c,可知程序运行在cpu_exec()函数中,-1转成无符号数即为最大能表示的数,所以程序会全部执行完。我们只需要把-1改成si后面的参数即可。(si后面的参数默认不能大于等于10)
static int cmd_si(char *args) {
int step;
if (args == NULL) step = 1;
else sscanf(args, "%d", &step);
cpu_exec(step);
return 0;
}
打印寄存器
前面实现的寄存器如何打印出来呢?一种方法是直接打印gpr数组,另一种方式是利用enum数组,在NEMU/nemu/include/cpu/reg.h里:
enum { R_EAX, R_ECX, R_EDX, R_EBX, R_ESP, R_EBP, R_ESI, R_EDI };
同时利用文件最下面这些实现求值:
#define reg_l(index) (cpu.gpr[check_reg_index(index)]._32)
#define reg_w(index) (cpu.gpr[check_reg_index(index)]._16)
#define reg_b(index) (cpu.gpr[check_reg_index(index) & 0x3]._8[index >> 2])
extern const char* regsl[];
extern const char* regsw[];
extern const char* regsb[];
看不懂上面啥意思?利用CTags进行函数跳转!如果用vscode或者sublime建议搜索相关CTags拓展包并安装!
注:CTags很重要!!!!!
最终实现代码如下:(千万别忘了打印$eip这个寄存器!)
static int cmd_info(char *args) {
if (args[0] == 'r') {
int i;
for (i = R_EAX; i <= R_EDI ; i++) {
printf("$%s\t0x%08x\n", regsl[i], reg_l(i));
}
printf("$eip\t0x%08x\n", cpu.eip);
}
return 0;
}
另外,printf("0x%8x")表示输出一个十六进制数,其中开头为0x,数字为8位,不足8位用0补齐。
扫描内存
找到swaddr_read函数,该函数实现了地址的读取功能,通过阅读代码知道其意思,其他的很显然了。
记得阅读代码!
static int cmd_x(char *args){
if (args == NULL) {
printf("Wrong Command!\n");
return 0;
}
int num,exprs;
sscanf(args,"%d%x",&num,&exprs);
int i;
for (i = 0;i < N;i ++){
printf("0x%8x 0x%x\n",exprs + i*32,swaddr_read(exprs + i * 32,32));
}
return 0;
}
必做任务 3:实现算术表达式的词法分析
首先,要在expr.c文件的rule结构体中添加正则表达式,同时对于一些特定的类型写在enum里,比如截取的这两个:
{"\\b[0-9]+\\b", NUMBER},
{"-", "-"},
NUMBER就需要写在enum中。
词法分析在make_token函数中,有一个TODO标明了你要写的地方。这里我们只需要分是否为空格两种情况来写即可。如果通过正则表达式读入的是若干空格,则不存入tokens数组中,否则将其存放在数组中。
这里有一些很好的字符串有关的函数,在PA1中经常用到:
strlen,strcmp,strcpy,strncpy,自行查阅功能及用法,同时要注意char*类型如何截取,以及复制后末尾\0的影响。
大致截取过程如下:
char *substr_start = e + position;
int substr_len = pmatch.rm_eo;
strncpy(tokens[nr_token].str, substr_start, substr_len);
全部代码在这里就不贴出了~
必做 4:实现算术表达式的递归求值
根据实验指导书“递归求值”部分,我们可以知道下一步要实现的函数结构如下:
eval(p,q){
if (p > q){
...
}
else if (p == q){
...
}
else if (check_parentheses(p, q) == true){
...
return eval(p + 1, q - 1);
}
else {
...
}
}
eval是一个递归函数,用来求值,其中若p>q则显然不符合,直接跳出循环;若p==q则说明该位置应当是一个数值,直接判断tokens[p].type类型然后用sscanf转成数字返回就行。
那么对于p<q,又有两种情况,先要进行括号判断,即如果当前p到q区间类似于(1+2)情况,需要将括号去掉,取中间1+2递归计算值;如果不满足,则需要找到“主符号”(dominant operator)。
对于主符号的定义,你可以理解为是从右往左出现的第一个优先级最低的符号,因为它需要最后计算。比如1+2*3-4的主符号是-。由于在这个阶段只需要实现四则运算,所以优先级的概念可以模糊,只要认为+和-优先级低于*和/就行。
找到之后递归求出左右区间的值,再用switch进行计算值即可,具体框架已经在指导书中已经写得十分详细了。
需要注意,在check_parentheses()函数中不要把形如(1+2)*(3+4)的两边的括号匹配上,否则就会出错!
Tip:
check_parentheses()的实现利用循环从左往右遍历,进行左括号计数,遇到左括号加一,右括号减一,来判断两者是否匹配。
最后记得修改cmd_p使其可以计算表达式!
选做任务 1:实现带有负数的算术表达式的求值
区分负号和减号其实十分简单,因为当-被认为是负号,只有可能是以下情况:它是算式的第一个符号、它前面不是数字且它前面不是右括号(后续还有它前面不是寄存器或十六进制数)。
所以我们只需要make_token执行完了后,将tokens数组遍历一遍,将所有应当为负号的-的type修改掉即可。
在eval函数中,若识别到了负号是主符号(这个时候就得考虑负号优先级了),那么其必定没有左半边了,只有右半边,故此时直接将右边的表达式的值乘以-1后返回即可。
必做任务 5:实现更复杂的表达式求值
这个时候就得实现更复杂的表达式了,首先应当了解符号优先级。符号优先级表如下:(该表中优先级越大表示越后计算,即优先级大的为主符号)
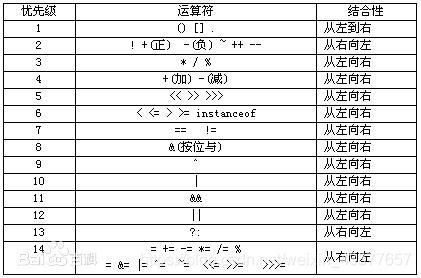
在从右往左找主符号时,记录下当前最大的优先级和该优先级第一次出现的位置。
特别的是,如果找到的主符号是优先级为2的时候,由于其是单目运算符,结合性与其他的相反,所以此时需要再从左往右扫描一遍,找到最左边的符号即为主符号。比如,-!1的主符号为-而不是!。
然后是正则表达式的问题。程序默认按rules[]中从上到下的顺序扫描匹配,所以正则表达式的顺序至关重要,比如对于&&必须放在&上面,否则将无法被识别。寄存器和十六进制数均可出现大写小写形式,正则表达式都得将其考虑进去,即$eax和$EAX都能被识别,0xaf、0Xaf、0xAF均能被识别。为了方便后面计算,建议将读入进来的内容全部转成小写。
当求寄存器的值的时候,我们应当利用前面打印寄存器的char数组和去除$符号的内容进行逐个比较,下面给出比较32位寄存器的代码片段:
int i;
for (i = R_EAX; i <= R_EDI ; i ++) {
if (strcmp(tokens[l].str, regsl[i]) == 0) {
break;
}
}
if (i > R_EDI) {
if (strcmp(tokens[l].str, "eip") == 0) {
num = cpu.eip;
}
} else return num = reg_l(i);
对于16位和8位寄存器的比较与之类似。
选做任务 2:实现指针解引用
这个就和前面负号的实现基本一模一样,不再赘述,指针解引用的优先级也为2。
必做任务 6:实现监视点池的管理
监视点的实现主要是链表的实现,不记得链表的实现建议复习复习。
先在neme\include\monitor\watchpoint.h中补充struct的内容(注明了TODO),因为监视点需要记录某个表达式的值,所以再声明一个char数组来存表达式,uint32_t类型来表示值即可。随后在#endif前加入函数声明:
WP* new_wp();
void free_wp(WP*);
因为这是.h文件,所以实现得去.c文件中实现,后续还要往这里面声明其他函数。
在watchpoint.c文件中完成这两个函数。要在写之前考虑清楚是“头插法”还是“尾插法”,什么时候会出现访问NULL,以及清空监视点时是否清空了该处之前记录的内容。
假设我新声明了一个监视点,如果当前已经存在不止一个监视点,应当这样将该点插入到尾段:(以下代码仅为示例,
new_node为新声明的节点,从free_中取出等操作并未写上)WP *h; h = head; while (h -> next != NULL){ h = h -> next; } h -> next = new_node;
必做任务 7:实现监视点
cmd_w函数
在声明监视点的时候,若监视点数量达上限(NR_WP = 32),需要提示用户无法声明。
每当申请成功,需要有提示信息,提示该监视点的编号、表达式以及当前的值。
info w函数
需要实现一个遍历所有监视点的函数,相信这个不是很难。然后将监视点的编号、表达式以及当前的值按顺序输出。
cmd_d函数
也是遍历一遍所有监视点,然后找到要删的监视点,将其从head中移去并且重新加入free_中,若成功返回删除成功提示。
监视点的功能的实现
监视点是每当程序执行完某一行汇编语句后,判断是否有表达式的值发生了改变,如果有则将其输出出来,并将程序暂停等待下一个命令。
在cpu-exec.c中有个TODO标明了写判断监视点值是否改变的位置。再写一个遍历函数,这个函数返回一个bool类型,即是否有值发生改变。若有则
nemu_state = STOP;
需要注意的是,在这个函数里,如果监视点的值发生了改变,需要打印出来它的详细信息,即编号、表达式、旧值、新值,然后一定要把旧值更新成新的值!