单页扒手-基于Node的实现
做网站的朋友经常遇见别人的好看的页面,想保存到本地自己用,可是用以前的老办法网页另存为,发现很不好,规则不好处理,路径也不好处理,用这个网页克隆(单页模板扒手)就很好处理了,你只要输入你想要扒皮的网站地址,点击下载就可以了。
我就是最近看到一个很不错的后端的模板,想要扒下来,于是就上网找了个工具,叫做单页扒手。就是下面这个玩意儿。
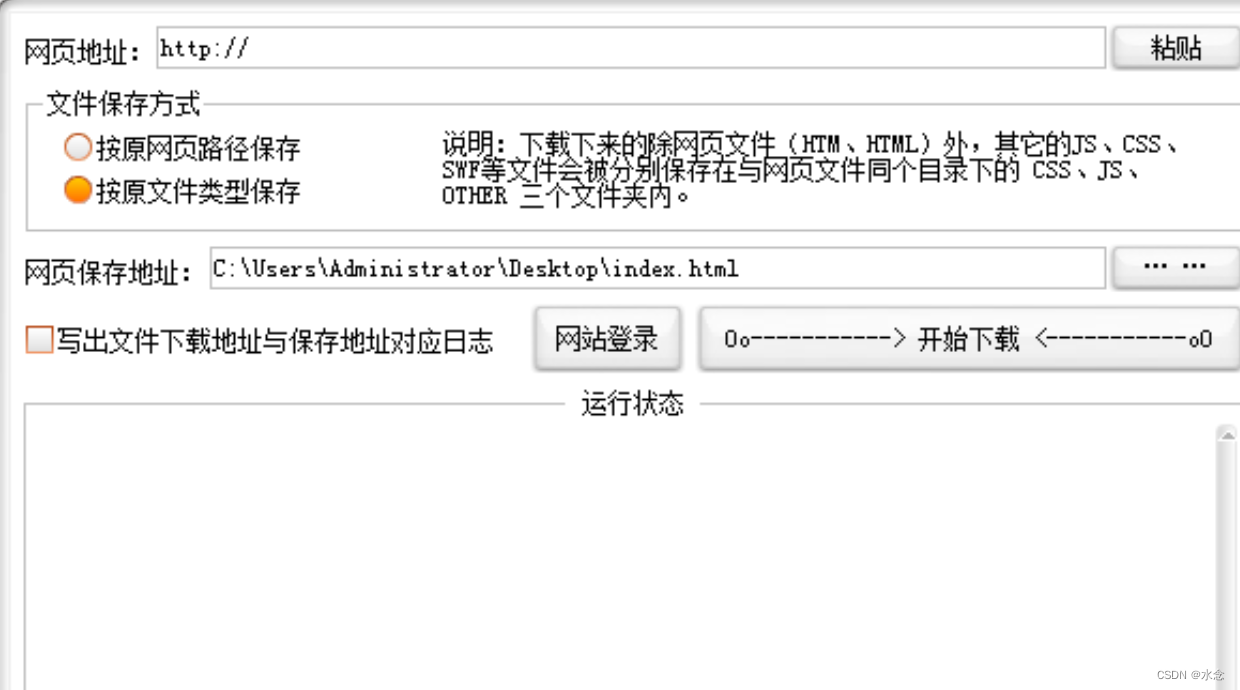
结果下载完成之后,居然给我报有病毒,当我再去找的时候,我突然间想起来,我TM是个不靠谱的程序员,为什么这次就不能给你靠谱点儿自己写一个呢?于是就默默的打开了我的编辑器,建了个工程PageDownload。
基本思路
首先说明一点儿,我的这个单页抓包的东西,只是一个基础的,下载的内容也都是相对来说比较简单的(Just For Fun)。
- 给一个网页地址,请求加载网页的Html,然后将一个页面进行保存。
- 解析Html,查找Html中所有的资源(主要是CSS,JS和Image),以及连接,然后继续去请求,并且继续下载和保存。
- 如果连接的资源是Html的话,则继续进行解析然后下载
- 下载过的资源用记录下来,在遇到同样的资源的时候,需要进行检测,如果存在相同的资源,则不在进行下载和处理,避免进入死循环。
好了既然思路都有了,那就开始写代码吧。
可能存在的问题与解决:
- 嵌入的资源是第三方资源,与本站的地址不符我们需要处理?(有些模板网站嵌入的有谷歌字体什么的,这些暂时先不处理)。
- 某些Css中所引用的资源比如说图片,svg图标字体应该如何去解析?这些个暂时先不处理,毕竟这些都是少量的,
- 如果连接的第三方连接会很深应该如何处理?
所需要的第三方包
再开始之前我们根据上面的实现思路先安装一些需要用到的包:
- request(网络请求)
- cheerio(一个很好用的Html解析工具,效率非常高)
- fs-extra(fs-extra模块是系统fs模块的扩展,提供了更多便利的API,并继承了fs模块的API,本文详细介绍所有操作方法,方便读者更好的操作服务端文件)
基本的代码实现
这里就不在瞎说,直接贴代码,具体的代码解释参考代码中的注释:
const path = require('path');
const cheerio = require('cheerio');
const fse = require('fs-extra');
const request = require('request');
// 需要爬取的页面的地址
const HOST = 'https://offsetcode.com/themes/messenger/2.2.0/';
// 爬取之后输出的位置
const OUT_PATH = path.join(__dirname, 'messenger');
// 用来记录已经下载过的资源,防止重复下载
const loadedResourceMap = new Map();
const loadErrorSet = new Set();
async function downloadHtmlPage(urlObj) {
if (!fse.existsSync(urlObj.outputPath)) {
await downloadHtmlResource(urlObj)
} else {
loadedResourceMap.set(urlObj.requestUrl, urlObj);
return;
}
if (fse.existsSync(urlObj.outputPath)) {
const fileData = fse.readFileSync(urlObj.outputPath, {encoding: 'utf-8'});
if (fileData) {
const { htmlResource = [], notHtmlResource = [] } = analysisHtmlData(fileData, urlObj.currentPath);
for (let index = 0; index < notHtmlResource.length; index++) {
if (!loadedResourceMap.has(notHtmlResource[index].requestUrl)) {
downloadNotHtmlResource(notHtmlResource[index]);
}
}
for (let index = 0; index < htmlResource.length; index++) {
if (!loadedResourceMap.has(htmlResource[index].requestUrl)) {
await downloadHtmlPage(htmlResource[index]);
}
}
}
}
}
function downloadNotHtmlResource(urlObj) {
fse.ensureDirSync(urlObj.outputDir);
request(urlObj.requestUrl)
.pipe(fse.createWriteStream(urlObj.outputPath))
loadedResourceMap.set(urlObj.requestUrl, urlObj);
console.log('下载成功:', urlObj.requestUrl, '>>>>>>>>>>>', urlObj.outputPath);
}
async function downloadHtmlResource(urlObj) {
return new Promise(resolve => {
request(urlObj.requestUrl, (err, response) => {
if (err) {
console.log('下载失败:', urlObj.requestUrl);
loadErrorSet.add(urlObj.requestUrl);
} else if (response.statusCode === 200) {
console.log('请求成功!');
const body = response.body;
fse.ensureFileSync(urlObj.outputPath);
fse.writeFileSync(urlObj.outputPath, body, { encoding: 'utf-8' });
loadedResourceMap.set(urlObj.requestUrl, urlObj);
console.log('下载成功:', urlObj.requestUrl, '>>>>>>>>>>>', urlObj.outputPath);
} else {
loadErrorSet.add(urlObj.requestUrl);
console.log(`下载失败${response.statusCode}:`, urlObj.requestUrl);
}
resolve();
})
})
}
function formatUrl(url, baseUrl = '/') {
if (url.startsWith(HOST)) {
url = url.replace(HOST, '');
}
if(url === 0 || url === '/') {
url = 'index.html';
// return {
// requestUrl: HOST + path.join(baseUrl, 'index.html'),
// outputDir: path.join(OUT_PATH, baseUrl),
// outputPath: path.join(OUT_PATH, baseUrl, 'index.html'),
// currentPath: baseUrl
// }
}
url = url.startsWith('/') ? url.substring(1) : url;
if (url.endsWith('/')) {
url = url + 'index.html';
}
const urlArr = url.split('/');
let lastFile = urlArr[urlArr.length - 1] || 'index.html';
const temp = urlArr.slice(0, urlArr.length - 1);
return {
requestUrl: HOST + path.join(baseUrl, temp.join('/'), lastFile),
outputDir: path.join(OUT_PATH, baseUrl, temp.join('/')),
outputPath: path.join(OUT_PATH, baseUrl, temp.join('/'), lastFile),
currentPath: path.join(baseUrl, temp.join('/'))
}
}
function isOtherHost(url) {
if (url.startsWith('http://') || url.startsWith('https://')) {
return !url.startsWith(HOST);
}
return false;
}
function isUseLessLink(href) {
return href.startsWith('javascript:');
}
function analysisHtmlData(htmlData, baseUrl = '/') {
if (!htmlData) {
return null;
}
const $ = cheerio.load(htmlData);
const htmlResource = [];
const notHtmlResource = []; // 这里主要放一些图片和script的资源连接,因为这两类资源都可以直接下载不用再做后期的处理
$('link').each((index, $item) => {
const href = $item.attribs.href;
if (href && href.endsWith('.css') && !isOtherHost(href)) {
const urlObject = formatUrl(href, baseUrl);
if (!loadedResourceMap.has(urlObject.requestUrl) && !loadErrorSet.has(urlObject.requestUrl)) {
notHtmlResource.push(urlObject);
}
}
});
$('img, script').each((index, $item) => {
const src = $item.attribs.src;
const srcTempArr = src ? src.split('.') : [];
if (srcTempArr.length) {
const resourceSuffix = srcTempArr[srcTempArr.length - 1];
const canAddSuffixs = new Set(['js', 'png', 'jpg', 'jpeg', 'svg', 'gif']);
if (canAddSuffixs.has(resourceSuffix) && !isOtherHost(src)) {
const urlObject = formatUrl(src, baseUrl);
if (!loadedResourceMap.has(urlObject.requestUrl) && !loadErrorSet.has(urlObject.requestUrl)) {
notHtmlResource.push(urlObject);
}
}
}
});
$('a').each((index, $item) => {
const href = $item.attribs.href;
if (href && !href.startsWith('#') && !isUseLessLink(href) && !href.startsWith('javascript:') && !isOtherHost(href)) {
const urlObject = formatUrl(href, baseUrl);
if (!loadedResourceMap.has(urlObject.requestUrl) && !loadErrorSet.has(urlObject.requestUrl)) {
htmlResource.push(urlObject);
}
}
});
return {
htmlResource,
notHtmlResource
};
}
function main() {
const urlObj = formatUrl('');
downloadHtmlPage(urlObj);
}
main();写完代码,跑起来,接下来就是静静的等待。下载完成后,运行页面是可以的。
小结
技术是用来解决问题和需求,离开问题和需求,技术的价值就真的很低很低。