细粒度分类:RA-CNN论文笔记——Look Closer to See Better: Recurrent Attention Convolutional Neural Network
细粒度分类:RA-CNN论文笔记——Look Closer to See Better: Recurrent Attention Convolutional Neural Network for Fine-grained Image Recognition
综述
论文题目:《Look Closer to See Better: Recurrent Attention Convolutional Neural Network for Fine-grained Image Recognition》
会议时间:IEEE Conference on Computer Vision and Pattern Recognition 2017 (CVPR, 2017)论文地址:https://openaccess.thecvf.com/content_cvpr_2017/papers/Fu_Look_Closer_to_CVPR_2017_paper.pdf
源码地址(PyTorch版本):https://github.com/jeong-tae/RACNN-pytorch
针对领域:细粒度图像分类(FGVC)
关键词:注意力机制、细粒度识别、多尺度区域定位
源码笔记链接:https://blog.csdn.net/qq_50001789/article/details/131352932?spm=1001.2014.3001.5501
主要思想
细粒度识别任务主要在于有区分度区域的定位和细粒度特征的学习,现有的方法主要是独立地解决这两个问题,在区域定位的学习中,传统的细粒度识别算法又需要额外的人工标注,这样做不仅工作量大,而且容易受到主观因素的干预。作者发现区域定位和特征学习可以相互促进,提出了循环注意力网络,网络的核心结构是注意力建议子网络(APN模块),只需要提供图片的标签,就可以让该子网络迭代产生由粗到细的多尺度注意力区域,进一步将其裁剪放大,学习放大后的微小差异,可以有效地提高细粒度特征提取的能力;并且提出了利用尺度内分类损失来优化特征提取能力、利用尺度间排序损失来优化区域定位能力,并且还提出了交替学习的训练策略,让特征提取学习和区域定位学习互相促进,交替优化。
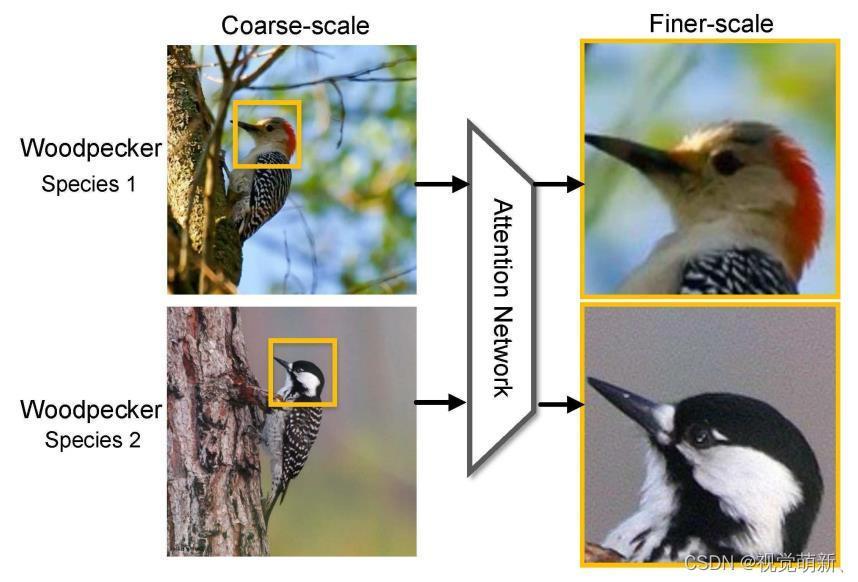
首先原图像输入到网络中,作为粗尺度,经过注意力网络,得到注意力区域,进一步将该区域裁剪放大,得到精细尺度。
网络的主要流程
具体流程见下图:
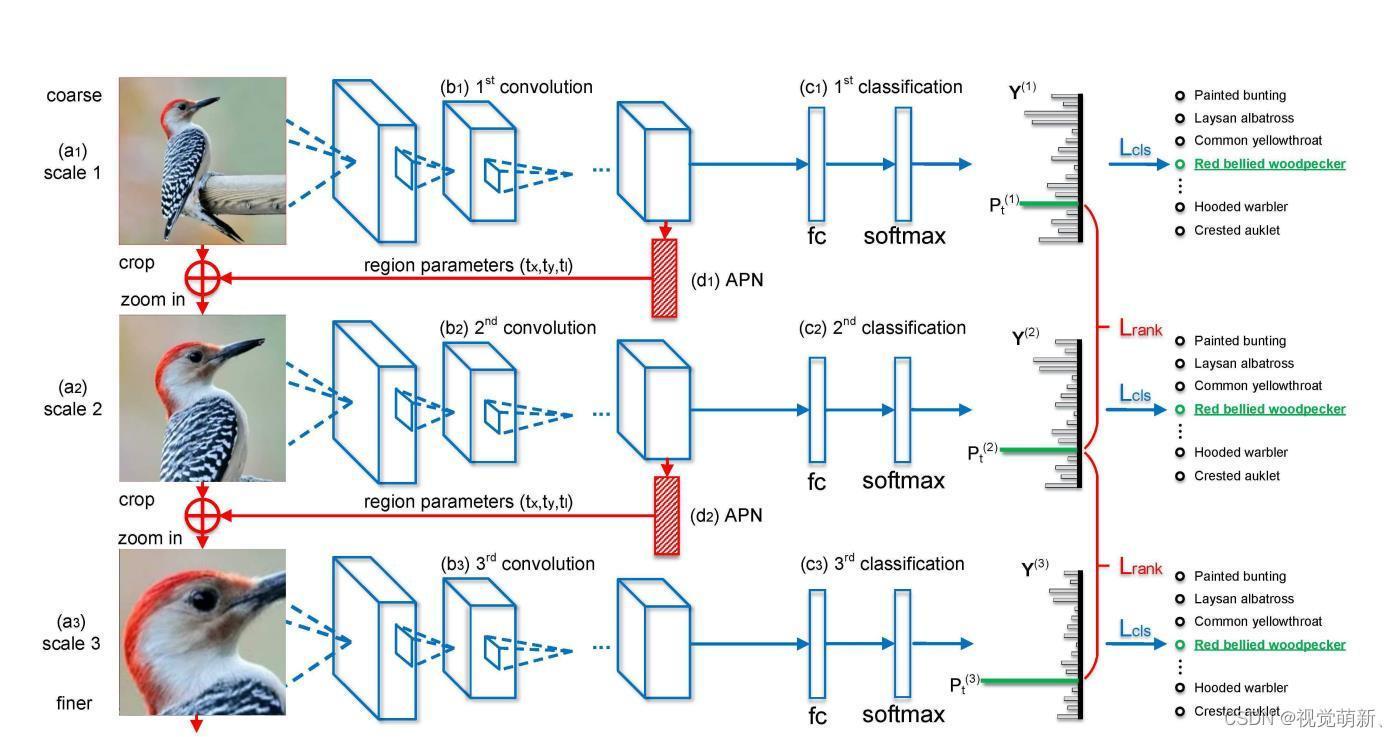
首先,先将原图像经过经典的特征提取网络(流程图中的b1、b2、b3)进行提取特征,得到特征图,具体公式如下:
P
(
X
)
=
f
(
W
c
∗
X
)
P(X)=f(W_c*X)
P(X)=f(Wc∗X)
其中 W c W_c Wc表示特征提取网络的参数, ∗ * ∗表示卷积运算, X X X表示原图像
之后特征图有两个去向,第一是特征图再经过全连接层(流程图中的c1、c2、c3)以及softmax函数,得到第一尺度图像的预测概率;第二是通过对原特征图进行某种运算,得到图像的注意力区域,注意力区域可以近似为由三个参数确定的正方形,具体表达式如下:
[
t
x
,
t
y
,
t
l
]
=
g
(
W
c
∗
X
)
[t_x,t_y,t_l]=g(W_c*X)
[tx,ty,tl]=g(Wc∗X)
其中,
t
x
t_x
tx和
t
y
t_y
ty表示正方形的中心坐标,
t
l
t_l
tl表示正方形边长的一半,g(·)可以表示为两个堆叠的全连接层来表示,由于本文中的APN模块(流程图中的
d
1
d_1
d1、
d
2
d_2
d2)是以弱监督的方式训练的,没有真实标签可以做比对,因此,必须通过特殊的损失函数加以约束,从而让网络的注意力区域朝物体所在(有区分度区域)的方向移动,训练过程以及损失函数在下文中讲解。
得到注意力区域之后,我们就可以以更高的分辨率关注那些有区分度的区域,将原图像进行裁剪放大,放大图像的微小差异,从而更好地提取图像的细粒度特征。为了能让注意力区域的定位过程在训练中得到优化,即让该过程变成一系列的连续函数(只有当函数是连续函数时,才能进行反向传播、更新参数),作者提出了一种利用二维脉冲函数来近似计算得到注意力区域的方法。
二维脉冲函数——注意力掩模
假设原始图像中的左上角是原点,x轴与y轴分别以从左到右、从上到下的方向为正方向,裁剪的矩形区域可以由左上角和右下角两个坐标点表示,两个点的计算公式如下:
t
x
(
t
l
)
=
t
x
−
t
l
,
t
y
(
t
l
)
=
t
y
−
t
l
,
t
x
(
b
r
)
=
t
x
+
t
l
,
t
y
(
b
r
)
=
t
y
+
t
l
.
t_{x(tl)}=t_x-t_l,\quad t_{y(tl)}=t_y-t_l,\\ t_{x(br)}=t_x+t_l,\quad t_{y(br)}=t_y+t_l.
tx(tl)=tx−tl,ty(tl)=ty−tl,tx(br)=tx+tl,ty(br)=ty+tl.
其中,
t
x
(
t
l
)
t_{x(tl)}
tx(tl)与
t
y
(
t
l
)
t_{y(tl)}
ty(tl)确定左上角的点,
t
x
(
b
r
)
t_{x(br)}
tx(br)与
t
y
(
b
r
)
t_{y(br)}
ty(br)确定右下角的点。
当得到注意力区域的坐标时,可以通过该坐标确定一个注意力掩模图,该图与原图像大小一致,图上的数据可以有效地代表原图的注意力区域分布,靠近注意力区域的数据系数趋近于1,远离注意力区域的数据系数趋近于0。最理想的是通过阶跃函数来实现,但由于阶跃函数不连续,因此只能选一个无限接近于阶跃函数的连续函数来生成注意力掩模。在这篇文章中,作者引入了带有系数k的sigmoid函数,该函数定义如下:
h
(
x
)
=
1
1
+
e
−
k
x
h(x)=\frac{1}{1+e^{-kx}}
h(x)=1+e−kx1
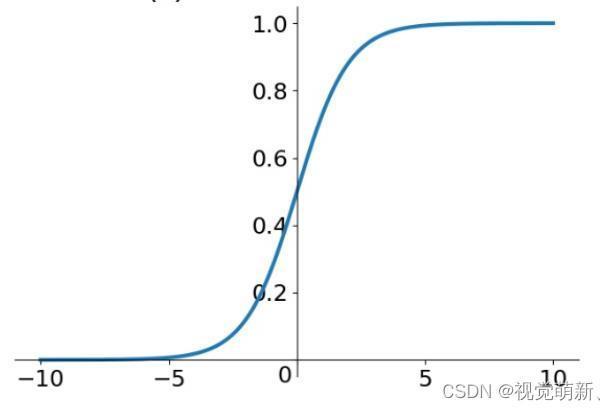
k越大,函数图像越陡,当k足够大时,就可以近似成阶跃函数。构建好近似阶跃函数的h(·)时,再构建如下函数,计算得到注意力掩模图:
M
(
⋅
)
=
[
h
(
x
−
t
x
(
t
l
)
)
−
h
(
x
−
t
x
(
b
r
)
)
]
⋅
[
h
(
y
−
t
y
(
t
l
)
)
−
h
(
y
−
t
y
(
b
r
)
)
]
M(·)=[h(x-t_{x(tl)})-h(x-t_{x(br)})]·[h(y-t_{y(tl)})-h(y-t_{y(br)})]
M(⋅)=[h(x−tx(tl))−h(x−tx(br))]⋅[h(y−ty(tl))−h(y−ty(br))]
其中,
x
x
x,
y
y
y是当前点的坐标
注意力掩模图计算过程的通俗解释:
定位注意力区域的两个坐标点可以将原图像划分为九个区域,具体见下图

其中⑤号区域为注意力区域,两个蓝点为用于定位区域的坐标点
以x为例:
-
当 x < t x ( t l ) x<t_{x(tl)} x<tx(tl),即坐标点位于①④⑦时, x − t x ( t l ) < 0 x-t_{x(tl)}<0 x−tx(tl)<0并且 x − t x ( b r ) < 0 x-t_{x(br)}<0 x−tx(br)<0,因此 h ( x − t x ( t l ) ) ≈ h ( x − t x ( b r ) ) ≈ 0 h(x-t_{x(tl)})≈h(x-t_{x(br)})≈0 h(x−tx(tl))≈h(x−tx(br))≈0
-
当 t x ( t l ) < x < t x ( b r ) t_{x(tl)}<x<t_{x(br)} tx(tl)<x<tx(br),即坐标点位于②⑤⑧时, x − t x ( t l ) > 0 x-t_{x(tl)}>0 x−tx(tl)>0并且 x − t x ( b r ) < 0 x-t_{x(br)}<0 x−tx(br)<0,因此 h ( x − t x ( t l ) ) ≈ 1 , h ( x − t x ( b r ) ) ≈ 0 h(x-t_{x(tl)})≈1,h(x-t_{x(br)})≈0 h(x−tx(tl))≈1,h(x−tx(br))≈0
-
当 t x ( b r ) < x t_{x(br)}<x tx(br)<x,即坐标点位于③⑥⑨时, x − t x ( t l ) > 0 x-t_{x(tl)}>0 x−tx(tl)>0并且 x − t x ( b r ) > 0 x-t_{x(br)}>0 x−tx(br)>0,因此 h ( x − t x ( t l ) ) ≈ h ( x − t x ( b r ) ) ≈ 1 h(x-t_{x(tl)})≈h(x-t_{x(br)})≈1 h(x−tx(tl))≈h(x−tx(br))≈1
因此,只有当x位于②⑤⑧范围内时,M(·)才有可能不为零;同理,只有当y位于④⑤⑥时,M(·)才有可能不为零。综上所述,只有当x,y同时位于注意力所关注的区域时,注意力掩模图上的数据才趋近于1,否则数据趋近于零,因此,该注意力掩模图可以有效地代表注意力所关注的区域。
由于二维脉冲函数可以将关注区域和坐标点建立起函数解析式,因此在反向传播的过程中,可以很好地优化生成坐标点的过程,即APN网络的参数
裁剪放大
基于上述得到的注意力掩模图,首先将原图像与注意力掩模做逐元素点乘操作,让原图只保留注意力所关注的部分,具体公式如下:
X
a
t
t
=
X
⊙
M
(
t
x
,
t
y
,
t
l
)
X^{att}=X⊙M(t_x,t_y,t_l)
Xatt=X⊙M(tx,ty,tl)
其中, ⊙ ⊙ ⊙表示矩阵的点乘运算、 X a t t X^{att} Xatt表示经过注意力掩模凸显后的图像
经过点乘操作后,原图像的关注区域已经被凸显出来了,但还是难以从图像中提取有效的特征表示,因此,作者首先将关注区域裁剪出来,然后采用了双线性插值映射将原图像的关注区域进一步放大,计算公式如下:
X
a
m
p
=
∑
α
,
β
=
0
1
∣
1
−
α
−
{
i
λ
}
∣
∣
1
−
β
−
{
j
λ
}
∣
X
(
m
,
n
)
a
t
t
X^{amp}=\sum^1_{α,β=0}|1-α-\{\frac{i}{λ}\}||1-β-\{\frac{j}{λ}\}|X^{att}_{(m,n)}
Xamp=α,β=0∑1∣1−α−{λi}∣∣1−β−{λj}∣X(m,n)att
其中,
X
(
i
,
j
)
a
m
p
X_{(i,j)}^{amp}
X(i,j)amp为裁剪后的图像,
m
=
[
i
λ
]
+
α
m=[\frac{i}{λ}]+α
m=[λi]+α,
n
=
[
j
λ
]
+
β
n=[\frac{j}{λ}]+β
n=[λj]+β,
λ
λ
λ为上采样因子,等于放大的尺寸除
t
l
t_l
tl,
[
⋅
]
[·]
[⋅]和
{
⋅
}
\{·\}
{⋅}分别表示整数部分和小数部分
原图经过裁剪放大操作,不仅过滤了无关的区域信息,还凸显了有区分度的部位,放大了微小的差异,有利于下一尺度细粒度特征的学习。
损失函数
本文损失函数主要由尺度内分类损失以及尺度间排序损失构成,两个损失交替优化,使网络可以准确地定位注意力区域并且有效地学习细粒度特征的提取
尺度内分类损失
尺度内分类损失定义如下:
L
c
l
s
(
X
)
=
∑
s
=
1
3
L
c
r
o
(
Y
(
s
)
,
Y
∗
)
其中,
L
c
l
s
表示尺度内分类损失,
L
c
r
o
表示交叉熵损失
Y
(
s
)
表示第
s
尺度的预测值,
Y
∗
表示真实标签
L_{cls}(X)=\sum^3_{s=1}L_{cro}(Y^{(s)},Y^*)\\ 其中,L_{cls}表示尺度内分类损失,L_{cro}表示交叉熵损失\\ Y^{(s)}表示第s尺度的预测值,Y^*表示真实标签
Lcls(X)=s=1∑3Lcro(Y(s),Y∗)其中,Lcls表示尺度内分类损失,Lcro表示交叉熵损失Y(s)表示第s尺度的预测值,Y∗表示真实标签
该损失主要优化卷积层和分类层的参数,确保在每个尺度下都具有足够的特征提取能力。
尺度间排序损失
尺度间排序损失定义如下:
L
r
a
n
k
(
p
t
(
s
)
,
p
t
(
s
+
1
)
)
=
m
a
x
{
0
,
p
t
(
s
)
−
p
t
(
s
+
1
)
+
m
a
r
g
i
n
}
其中,
p
t
s
和
p
t
(
s
+
1
)
分别表示第
s
尺度和第
s
+
1
尺度正确类别上的预测概率,
m
a
r
g
i
n
为边界值
L_{rank}(p^{(s)}_t,p^{(s+1)}_t)=max\{0,p^{(s)}_t-p^{(s+1)}_t+margin\}\\ 其中,p^{s}_t和p^{(s+1)}_t分别表示第s尺度和第s+1尺度正确类别上的预测概率,margin为边界值
Lrank(pt(s),pt(s+1))=max{0,pt(s)−pt(s+1)+margin}其中,pts和pt(s+1)分别表示第s尺度和第s+1尺度正确类别上的预测概率,margin为边界值
这个损失函数要求细尺度的预测概率要大于粗尺度的预测概率加上边界值margin。通过这个损失的优化,网络会以粗尺度的预测概率为参考,并且作用到细尺度上,使网络的注意力区域逐渐关注最有区分度的部位,从而生成更高概率的预测值。
两种损失函数对应的功能不同,因此参与的优化过程也不同,尺度内分类损失主要用于特征提取的优化,而尺度间排序损失主要用于注意力区域定位的优化,
训练流程
首先,三个尺度的特征提取网络都初始化为VGG19(这里也可以换成其他的模型),并且加载ImageNet训练好的预训练参数
APN的预训练:
首先对APN网络进行预训练,由于图像经过特征提取后,响应值越高的部位越有可能存在物体,因此,作者利用以下规则确定标准的矩形框:
①提取原图像中最后一个卷积层,通过搜索响应值最高的点确定正方形框的中心点
②正方形边长为原始图像边长的一半、
确定好标准的关注区域后,再构建损失函数(可以用smooth L1函数),不断优化APN网络的参数,使其关注区域往响应值高的区域靠拢。
交替训练:
当初始化完APN网络参数时,就到了网络整体参数的训练过程了,具体过程如下:
首先保持APN参数的不变,并且在三个尺度上优化尺度内分类损失,从而达到优化网络的特征提取层和分类层参数的目的;然后再将特征提取层和分类层的参数固定,切换到优化尺度间排序损失,从而优化APN的网络参数。这两个过程是迭代进行的,直到两部分损失在训练过程中不再变化,可以有效地使细粒度特征提取的学习以及注意力区域定位的学习相互促进,共同优化。
注意:每个尺度预测的
t
l
都被限制为不低于上一尺度的
1
3
,
避免裁剪的区域太小导致物体结构不完整
注意:每个尺度预测的t_l都被限制为不低于上一尺度的\frac{1}{3},避免裁剪的区域太小导致物体结构不完整
注意:每个尺度预测的tl都被限制为不低于上一尺度的31,避免裁剪的区域太小导致物体结构不完整
APN参数优化原理
我们通过计算tx,ty,tl的导数来说明注意力学习的机制,由于这三者有类似的推导过程,因此这里只以tx为例,通过链式法则来计算导数,以图像左上角为原点。
首先,我们计算h(x)的导数,
h
(
x
)
=
1
1
+
e
−
k
x
h
′
(
x
)
=
k
e
−
k
x
(
1
+
e
−
k
x
)
2
=
k
2
+
e
k
x
+
e
−
k
x
h(x)=\frac{1}{1+e^{-kx}}\\ h'(x)=\frac{ke^{-kx}}{(1+e^{-kx})^2}=\frac{k}{2+e^{kx}+e^{-kx}}
h(x)=1+e−kx1h′(x)=(1+e−kx)2ke−kx=2+ekx+e−kxk
分析易得,h’(x)的图像如下:
进一步计算M(·)对tx的偏导,
M
(
⋅
)
=
[
h
(
x
−
t
x
+
t
l
)
−
h
(
x
−
t
x
−
t
l
)
]
⋅
[
h
(
y
−
t
y
(
t
l
)
)
−
h
(
y
−
t
y
(
b
r
)
)
]
M
′
(
t
x
)
=
[
−
h
(
x
−
t
x
+
t
l
)
+
h
(
x
−
t
x
−
t
l
)
]
⋅
[
h
(
y
−
t
y
(
t
l
)
)
−
h
(
y
−
t
y
(
b
r
)
)
]
M(·)=[h(x-t_x+t_l)-h(x-t_x-t_l)]·[h(y-t_{y(tl)})-h(y-t_{y(br)})]\\ M'(t_x)=[-h(x-t_x+t_l)+h(x-t_x-t_l)]·[h(y-t_{y(tl)})-h(y-t_{y(br)})]
M(⋅)=[h(x−tx+tl)−h(x−tx−tl)]⋅[h(y−ty(tl))−h(y−ty(br))]M′(tx)=[−h(x−tx+tl)+h(x−tx−tl)]⋅[h(y−ty(tl))−h(y−ty(br))]
设
a
=
[
h
(
y
−
t
y
(
t
l
)
)
−
h
(
y
−
t
y
(
b
r
)
)
]
,
a
∈
R
a=[h(y-t_{y(tl)})-h(y-t_{y(br)})],a\in R
a=[h(y−ty(tl))−h(y−ty(br))],a∈R,可得
M
′
(
t
x
)
=
a
[
−
h
(
x
−
t
x
+
t
l
)
+
h
(
x
−
t
x
−
t
l
)
]
M'(t_x)=a[-h(x-t_x+t_l)+h(x-t_x-t_l)]
M′(tx)=a[−h(x−tx+tl)+h(x−tx−tl)],结合h’(x)的图像分析易得,
M
(
⋅
)
M(·)
M(⋅)对
t
x
t_x
tx的偏导图像函数如下:
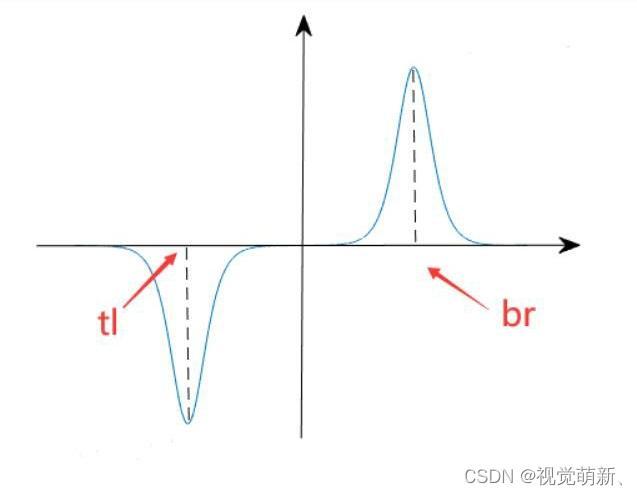
由图像可知,当x趋近于
t
x
−
t
l
t_x-t_l
tx−tl,即趋近于注意力区域的左边界时,导数值小于零;当x趋近于
t
x
+
t
l
t_x+t_l
tx+tl,即趋近于注意力区域的右边界时,导数值大于零,
t
x
t_x
tx有增大的趋势。因此,可以将
M
(
⋅
)
M(·)
M(⋅)对
t
x
t_x
tx的偏导总结成如下式子:
M
′
(
t
x
)
=
{
<
0
,
x
→
t
x
(
t
l
)
>
0
,
x
→
t
x
(
b
r
)
=
0
,
o
t
h
e
r
w
i
s
e
M'(t_x)=\left\{ \begin{matrix} <0,\quad &x\to t_{x(tl)} \\ >0, \quad &x \to t_{x(br)} \\ =0, \quad &otherwise \end{matrix} \right.
M′(tx)=⎩
⎨
⎧<0,>0,=0,x→tx(tl)x→tx(br)otherwise
通过上述分析,我们可以得到,当图像中响应值高的区域位于掩模区域的左侧时,掩模中心会有左移(tx减小)的趋势;当图像中响应值高的区域位于掩模区域的右侧时,掩模中心会有右移(tx增大)的趋势;其他情况下不变。
同理可以分析得到M(·)对
t
y
t_y
ty的偏导式子如下:
M
′
(
t
y
)
=
{
<
0
,
y
→
t
y
(
t
l
)
>
0
,
y
→
t
y
(
b
r
)
=
0
,
o
t
h
e
r
w
i
s
e
M'(t_y)=\left\{ \begin{matrix} <0,\quad &y\to t_{y(tl)} \\ >0, \quad &y \to t_{y(br)} \\ =0, \quad &otherwise \end{matrix} \right.
M′(ty)=⎩
⎨
⎧<0,>0,=0,y→ty(tl)y→ty(br)otherwise
当图像中响应值高的区域位于掩模区域的上侧时,掩模中心会有上移(
t
y
t_y
ty减小)的趋势;当图像中响应值高的区域位于掩模区域的下侧时,掩模中心会有下移(
t
y
t_y
ty增大)的趋势;其他情况不变。
M
(
⋅
)
M(·)
M(⋅)对
t
l
t_l
tl的偏导式子如下:
M
′
(
t
l
)
=
{
>
0
,
x
→
t
x
(
t
l
)
o
r
x
→
t
x
(
b
r
)
o
r
y
→
t
y
(
b
r
)
o
r
y
→
t
y
(
t
l
)
<
0
,
o
t
h
e
r
w
i
s
e
M'(t_l)=\left\{ \begin{matrix} >0,\quad & x\to t_{x(tl)} \quad or \quad x \to t_{x(br)}\\ &or \quad y\to t_{y(br)} \quad or \quad y\to t_{y(tl)} \\ <0, \quad &otherwise \end{matrix} \right.
M′(tl)=⎩
⎨
⎧>0,<0,x→tx(tl)orx→tx(br)ory→ty(br)ory→ty(tl)otherwise
当图像中响应值高的区域位于掩模的边界时,掩模边界大小会有扩大的趋势(
t
l
t_l
tl增大);否则,掩模边界收缩(
t
l
t_l
tl减小)。
具体变换效果可以见下图,黑色点为导数值是负的点,即响应值高的点。
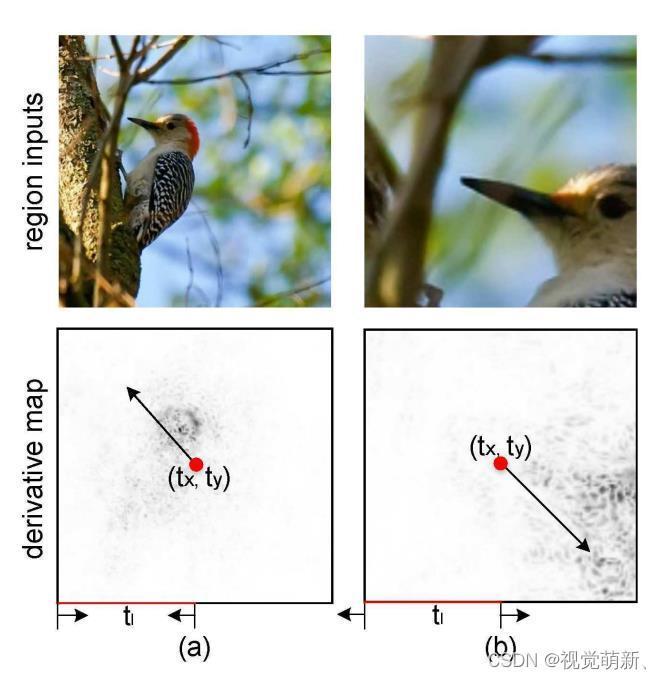
补充:
①导数值是负,代表该处的值对最终的损失是负影响,因此该处点的值对最终的分类有重要的积极影响,即该处的点是有区分度的区域,注意力的关注区域应该往这些点上靠拢。
②响应值高的区域:就是对最终分类有积极影响的区域,往往这些区域对应的权重系数都比较高。
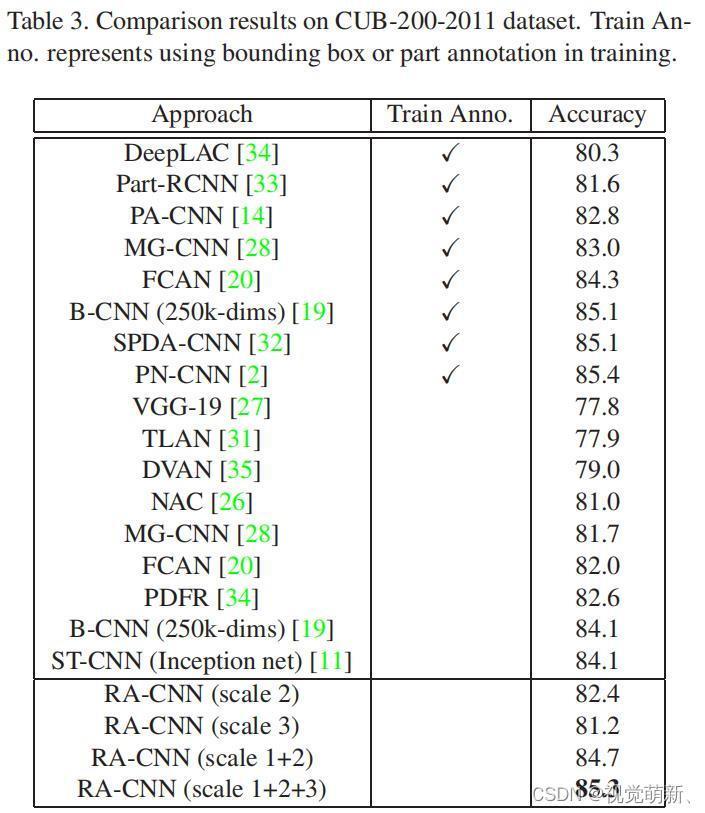
精度对比
CUB-200-2011
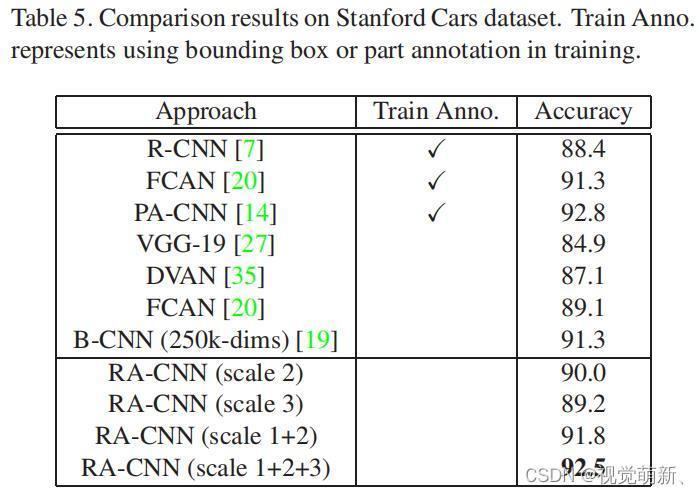
Stanford Cars
注:以上仅是笔者的个人见解,若有问题或者不清楚的地方,欢迎沟通交流。