论文阅读:Face Deblurring using Dual Camera Fusion on Mobile Phones
今天介绍一篇发表在 ACM SIGGRAPH 上的文章,是用手机的双摄系统来做人脸去模糊的工作。这也是谷歌计算摄影研究组的工作。
快速运动物体的运动模糊在摄影中是一个一直以来的难题,在手机摄影中也是非常常见的问题,尤其在光照不足,需要延长曝光时间的场景。最近几年,我们也看到了图像去模糊领域的巨大进步,不过大多数的图像去模糊方法的算法开销很高,需要依赖很高的算力,同时在处理高分辨率图像时还存在局限于不足。为了实现更轻量,效果更好的图像去模糊算法,文章作者提出了一种新的人脸去模糊方法,这个算法基于手机的双摄系统。当检测到场景中有运动物体的时候,会触发其中一路的参考摄像头,比如超广角,拍摄一张短曝光的图像,同时主摄拍摄一张正常曝光的图像,这样的话,超广角拍摄的图像是清晰的,但是噪声较多(曝光时间端,信噪比低),同时主摄拍摄的图像噪声少,但是会有模糊(曝光时间长,信噪比高)。文章作者用机器学习的模型取对齐两路图像,同时进行融合,最终输出的图像清晰,没有运动模糊。文章开发的算法在谷歌 Pixel 6 上的运行时间开销在 463ms,算法效率很高。文章中的实验,也展示了该算法的优势与鲁棒性。文章作者声称,他们的工作是第一个可以在手机上稳定可靠地在不同运动及光照环境下运行的人脸运动去模糊算法。
文章提出的解决方案建立在下面两个基础之上:
- 需要有双摄的手机系统,目前主流的手机都有双摄,文章中用到的双摄系统是主摄 W \mathbf{W} W 和超广角 U W \mathbf{UW} UW
- 能够同步曝光,同步自动白平衡,为了便于两路图像后续的对齐与融合
实际使用的时候,系统会同时拍摄一张正常曝光的主摄图像以及短曝光的超广角图像。这两组图像反映了不同的拍摄视角,不同的噪声水平以及颜色。文章训练一个 CNN 网络,对齐,融合这两路图像的 RAW 图中的人脸区域,得到一张干净清晰的 RAW 格式的人脸区域,融合后的 RAW 图会送入一个标准的图像 ISP 系统做后续的处理。文章作者声称比起同一路的长短曝融合的方法,双摄系统的方法可以做到时间上的对齐,进而可以得到更好的融合效果。
这篇文章使用的主摄 W \mathbf{W} W FOV 是 8 0 ∘ 80^{\circ} 80∘,超广角 U W \mathbf{UW} UW FOV 是 10 7 ∘ 107^{\circ} 107∘。主摄和超广角基本是平行并排放置,超广角基本覆盖了主摄的视野。两路图像的分辨率都是 12M,一般来说,超广角 U W \mathbf{UW} UW sensor 的噪声水平会比主摄 W \mathbf{W} W sensor 的噪声水平要高。文章的融合算法,将两路图像作为输入,主摄 W \mathbf{W} W 作为源图像,超广角 U W \mathbf{UW} UW 作为需要融合的图像。当场景中物体运动被检测到,会启动双摄拍摄两路 RAW 图,主摄 W \mathbf{W} W 一路的曝光时间由手机的自动曝光算法确定,超广角一路的曝光时间被设置为主摄一路的 1 / N 1/N 1/N,文章中 N = 2 , 4 N=2, 4 N=2,4。
下图展示了文章整个的算法流程:
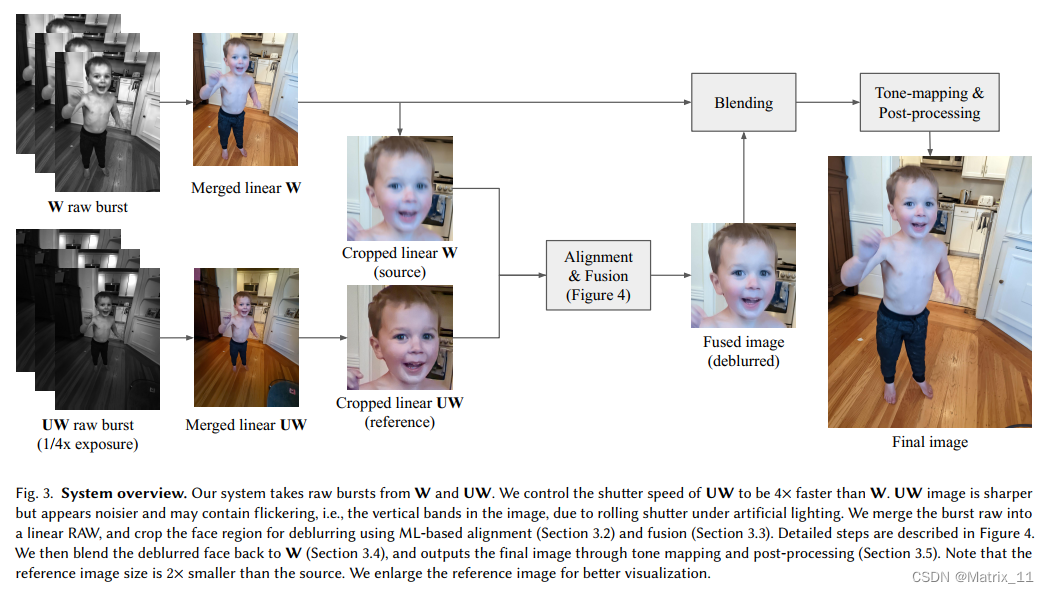
首先,将每一路的多帧 RAW 图分别做融合。然后对每一路融合后的 RAW 图结果做人脸检测和物体分割,进而确定人脸区域和需要去模糊的 ROI 区域,将这个区域 crop 出来,对 crop 出来的图像区域做融合,最后将融合后的 crop 区域与原来的 RAW 图进行 blend,再做一些后处理操作,包括锐化,全局以及局部的 tone-mapping 等。
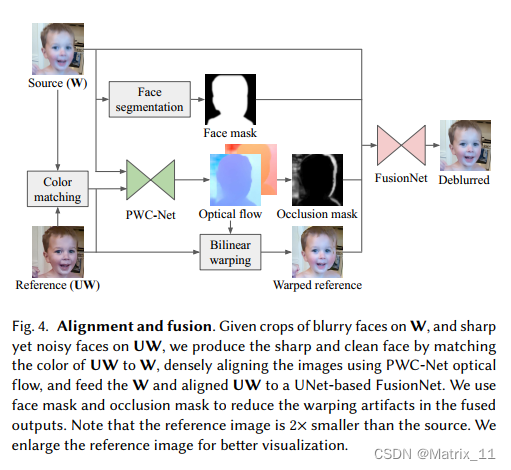
Pre-processing
- Fusion ROI and face mask
文章的工作聚焦在人脸区域,文章基于人脸检测,将最大的人脸框进行了一定的扩展,使得最终的 ROI 区域包括了人脸,头发,耳朵等。基于这个扩展的人脸框,文章用一个基于 UNet 的物体分割模型生成一个人脸 mask,并且对区域边缘进行一定的模糊。
- Color matching
由于两路镜头对应的 sensor 的性质不同,各自融合的图像会有一定的颜色差异,所以文章对两路图像做了一个颜色对齐,首先利用线性空间的颜色转换矩阵,计算一个归一化下的图:
I r e f n = C C M s r c − 1 ⋅ C C M r e f ⋅ I r e f (1) I_{ref}^{n} = CCM_{src}^{-1} \cdot CCM_{ref} \cdot I_{ref} \tag{1} Irefn=CCMsrc−1⋅CCMref⋅Iref(1)
C C M CCM CCM 是一个 3 × 3 3 \times 3 3×3 的颜色转换矩阵。
然后再将两路图像的均值进行对齐:
I ^ r e f = I r e f n μ r e f ⋅ μ s r c (2) \hat{I}_{ref} = \frac{I_{ref}^{n}}{\mu_{ref}} \cdot \mu_{src} \tag{2} I^ref=μrefIrefn⋅μsrc(2)
Image Alignment
接下来是图像对齐,文章还是用到了经典的 PWC-Net 训练了一个配准网络,为了适应手机图像的高分辨率,文章对 PWC-Net 做了一定程度改进,主要是通过下采样来提升网络可以 cover 的偏移程度。
F f w d = PWCNet ( ( I s r c ) ↓ , ( I ^ r e f ) ↓ ) ↑ (3) F_{fwd} = \text{PWCNet}((I_{src})_{\downarrow}, (\hat{I}_{ref})_{\downarrow})_{\uparrow} \tag{3} Ffwd=PWCNet((Isrc)↓,(I^ref)↓)↑(3)
获得位移向量场之后,再通过 warp 就可以得到配准后的图像:
I r e f ′ = W ( I ^ r e f ; F f w d ) (4) I_{ref}' = \mathbb{W}(\hat{I}_{ref}; F_{fwd}) \tag{4} Iref′=W(I^ref;Ffwd)(4)
文章中也介绍了对于 PWCNet 的一些轻量化的改进,包括剪枝,量化等操作。
对于遮挡区域的处理,文章也是沿用了一般的配准方法,利用 PWCNet 生成了前向的位移场 F f w d F_{fwd} Ffwd 以及反向的位移场 F b w d F_{bwd} Fbwd。然后通过前向 warp 与反向 warp 之间的误差来确定遮挡区域:
M o c c ( x ) = min ( s ⋅ ∥ W ( W ( x ; F f w d ) ; F b w d ) − x ∥ 2 , 1.0 ) (6) M_{occ}(\mathbf{x}) = \min(s \cdot \left \| \mathbb{W}(\mathbb{W}(\mathbf{x}; F_{fwd}); F_{bwd}) - \mathbf{x} \right \|_{2} , 1.0) \tag{6} Mocc(x)=min(s⋅∥W(W(x;Ffwd);Fbwd)−x∥2,1.0)(6)
Image Fusion
接下来是图像融合,文章中也是构建了一个网络模型来实现融合:
I f u s e d = FusionNet ( I s r c , I r e f ′ , M f a c e , M o c c ) + I s r c I_{fused} = \text{FusionNet}(I_{src}, I_{ref}', M_{face}, M_{occ}) + I_{src} Ifused=FusionNet(Isrc,Iref′,Mface,Mocc)+Isrc
网络输入的是源图像,配准后的参考图像,分割出来的人脸区域,以及遮挡区域,输出的是融合后的图像。
- Training data
这种去模糊的图像处理问题,比较困难的一个环节就是训练数据的构建,对于真实场景来说,输入的有模糊图像和参考图像很好获取,但是最终无模糊的 GT 图像很难获得,所以文章中也是用了模拟仿真的方式来构建训练数据集。首先针对静态场景,用主摄和超广角分别拍摄一张清晰图像,作为 GT,然后利用模拟的运动模糊核对 GT 做卷积,得到一张人脸区域是模糊的,背景区域是相对清楚的仿真退化图像。
I s r c = M b l u r ⋅ ( I G T ⊗ k ) + ( 1 − M b l u r ) ⋅ I G T + n (7) I_{src} = M_{blur} \cdot (I_{GT} \otimes k) + (1 - M_{blur}) \cdot I_{GT} + n \tag{7} Isrc=Mblur⋅(IGT⊗k)+(1−Mblur)⋅IGT+n(7)
- Training loss
图像融合网络的训练损失函数是常用的 L1 loss 和 VGG loss
L c o n t e n t = ∥ I f u s e d − I G T ∥ 1 (8) \mathcal{L}_{content} = \left \| I_{fused} - I_{GT} \right \|_{1} \tag{8} Lcontent=∥Ifused−IGT∥1(8)
L v g g = ∑ j w j ∥ V G G j ( I f u s e d ) − V G G j ( I G T ) ∥ 1 (9) \mathcal{L}_{vgg} = \sum_{j} w_j \left \| VGG_j(I_{fused}) - VGG_j(I_{GT}) \right \|_{1} \tag{9} Lvgg=j∑wj∥VGGj(Ifused)−VGGj(IGT)∥1(9)
文章中还增加了一个颜色一致性的损失函数
L c o l o r = ∥ G σ ( I f u s e d ) − G σ ( I G T ) ∥ 1 (10) \mathcal{L}_{color} = \left \| \mathcal{G}_{\sigma}(I_{fused}) - \mathcal{G}_{\sigma}(I_{GT}) \right \|_{1} \tag{10} Lcolor=∥Gσ(Ifused)−Gσ(IGT)∥1(10)
G σ \mathcal{G}_{\sigma} Gσ 就是一个高斯函数核。
最终的 loss 就是上面几种 loss 的加权和
w content L c o n t e n t + w vgg L v g g + w color L c o l o r (11) w_{\text{content}} \mathcal{L}_{content} + w_{\text{vgg}} \mathcal{L}_{vgg} + w_{\text{color}} \mathcal{L}_{color} \tag{11} wcontentLcontent+wvggLvgg+wcolorLcolor(11)
Image Blending
得到 ROI 区域的融合图像之后,接下来就是将去模糊后的图像与源图像的背景区域融合到一起:
I f i n a l = M b l e n d ⋅ I f u s e d + ( 1 − M b l e n d ) ⋅ I s r c (12) I_{final} = M_{blend} \cdot I_{fused} + (1 - M_{blend}) \cdot I_{src} \tag{12} Ifinal=Mblend⋅Ifused+(1−Mblend)⋅Isrc(12)
M b l e n d M_{blend} Mblend 就是最开始人脸区域,去掉遮挡区域,以及置信度低的配准区域
M b l e n d = min ( M f a c e − α M o c c − β M r e p r o j , 0 ) (13) M_{blend} = \min(M_{face} - \alpha M_{occ} - \beta M_{reproj}, 0) \tag{13} Mblend=min(Mface−αMocc−βMreproj,0)(13)
M r e p r o j = max R , G , B ( ∣ I s r c − I r e f ′ ∣ ) (14) M_{reproj} = \max_{R, G, B} (\left | I_src - I_{ref}' \right | ) \tag{14} Mreproj=R,G,Bmax( Isrc−Iref′ )(14)