Python.Scrapy爬取当当网畅销图书保存csv格式详细教程
初步了解scrapy框架爬虫的使用。

前言:
需要安装一下第三方库
在win下
pip install scrapy
pip install bs4
在mac下把pip改成pip3即可
一、创建scrapy项目
在cmd运行里输入(随便找个盘)
scrapy startproject dangdang
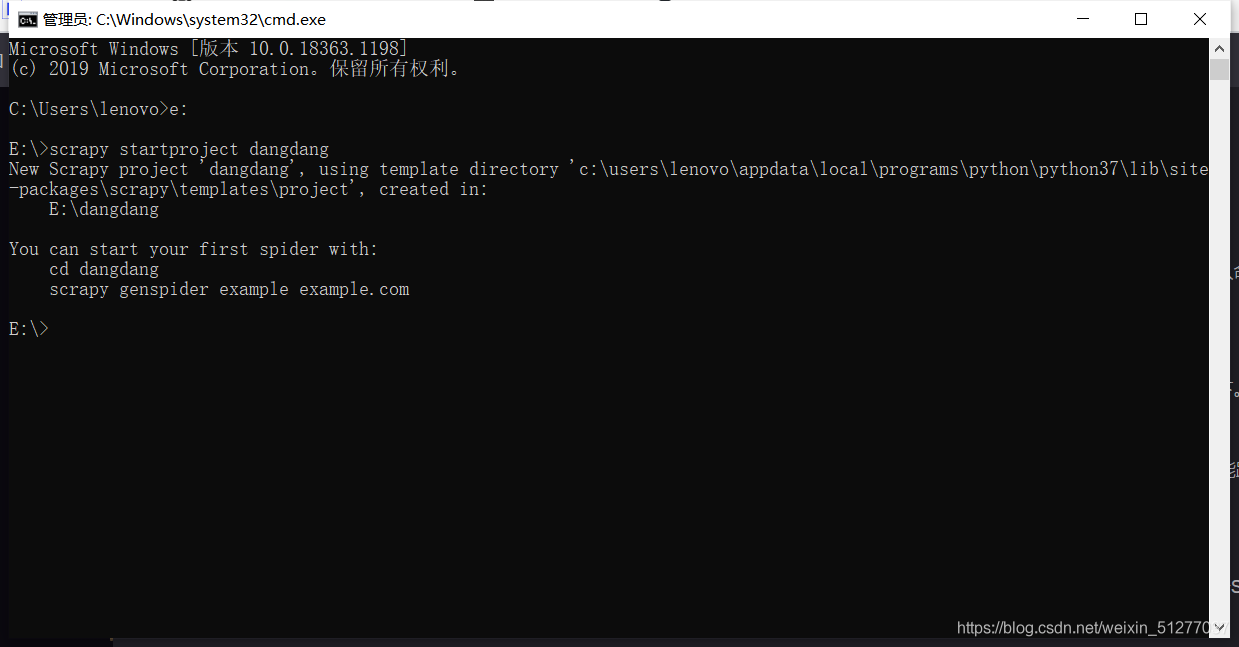
如上图创建成功,接下来在编译器中打开文件
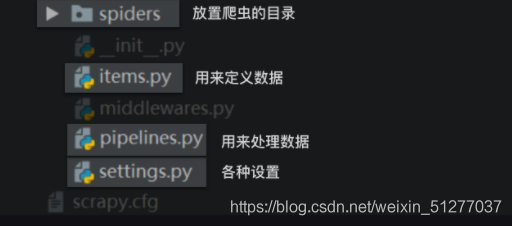
这些文件都是自动生成的 来解释说明一下部分文件
二、代码实现——编辑爬虫
——1.
接下来创建爬虫项目book.py(注意在spiders文件夹下创建)
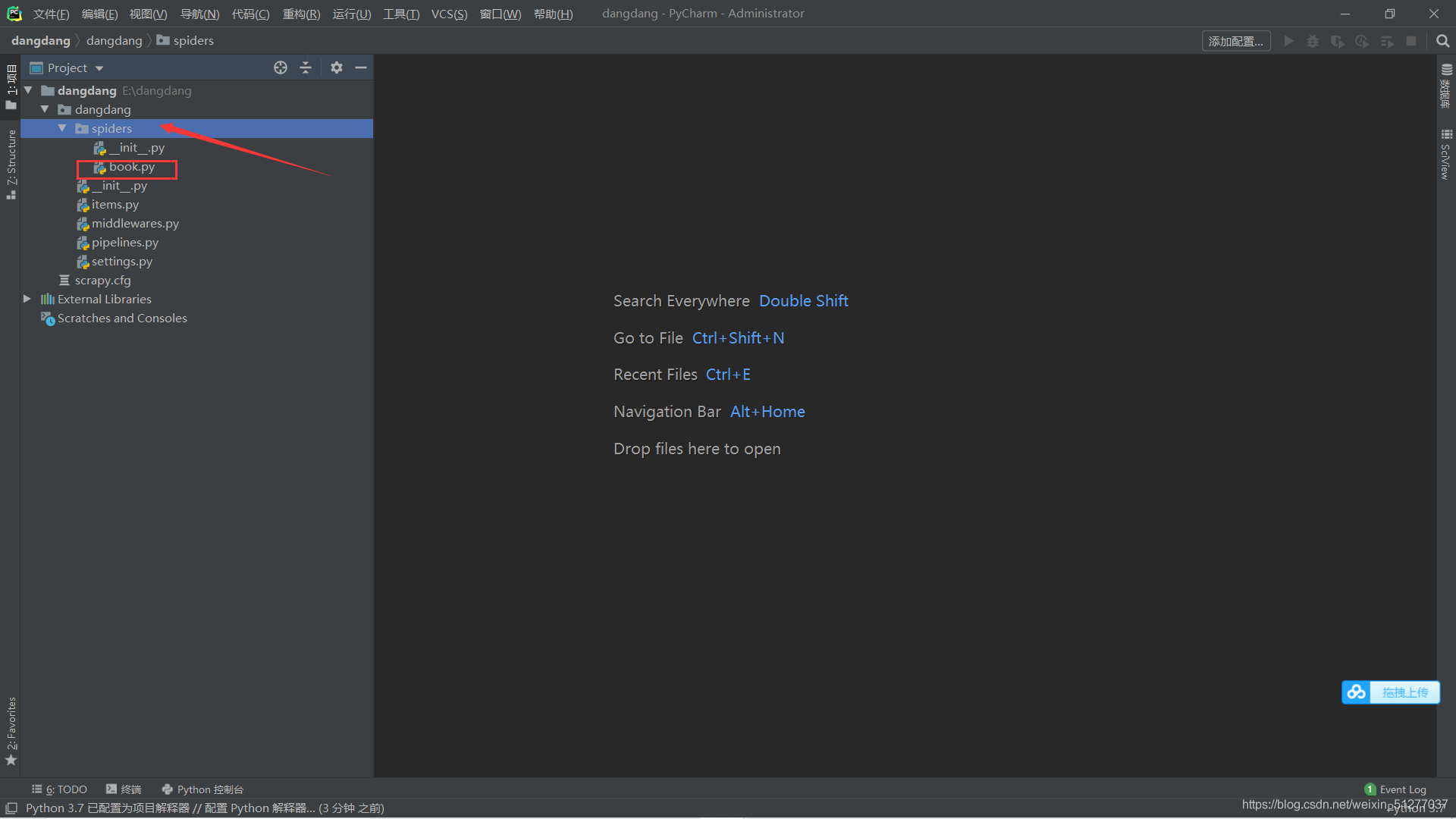
在book.py里填写爬虫代码
import scrapy
import bs4
from ..items import DangdangItem
# 需要引用DangdangItem,它在items里面。因为是items在book.py的上一级目录,..items这是一个固定用法。
class DangdangSpider(scrapy.Spider): #定义一个爬虫类DoubanSpider。
name = 'dangdang'
allowed_domains = ['http://bang.dangdang.com']
start_urls = []
for x in range(1, 4):
url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-year-2019-0-1-1' + str(x)
start_urls.append(url)
def parse(self, response): #parse是默认处理response的方法。
soup = bs4.BeautifulSoup(response.text, 'html.parser')
elements = soup.find('ul', class_="bang_list clearfix bang_list_mode").find_all('li')
for element in elements:
item = DangdangItem()
item['name'] = element.find('div', class_="name").find('a')['title']
item['author'] = element.find('div', class_="publisher_info").text
item['price'] = element.find('div', class_="price").find('span', class_="price_n").text
yield item# #yield item是把获得的item传递给引擎。
——2. 修改两个文件
接下来打开setting.py文件修改请求头和爬虫协议
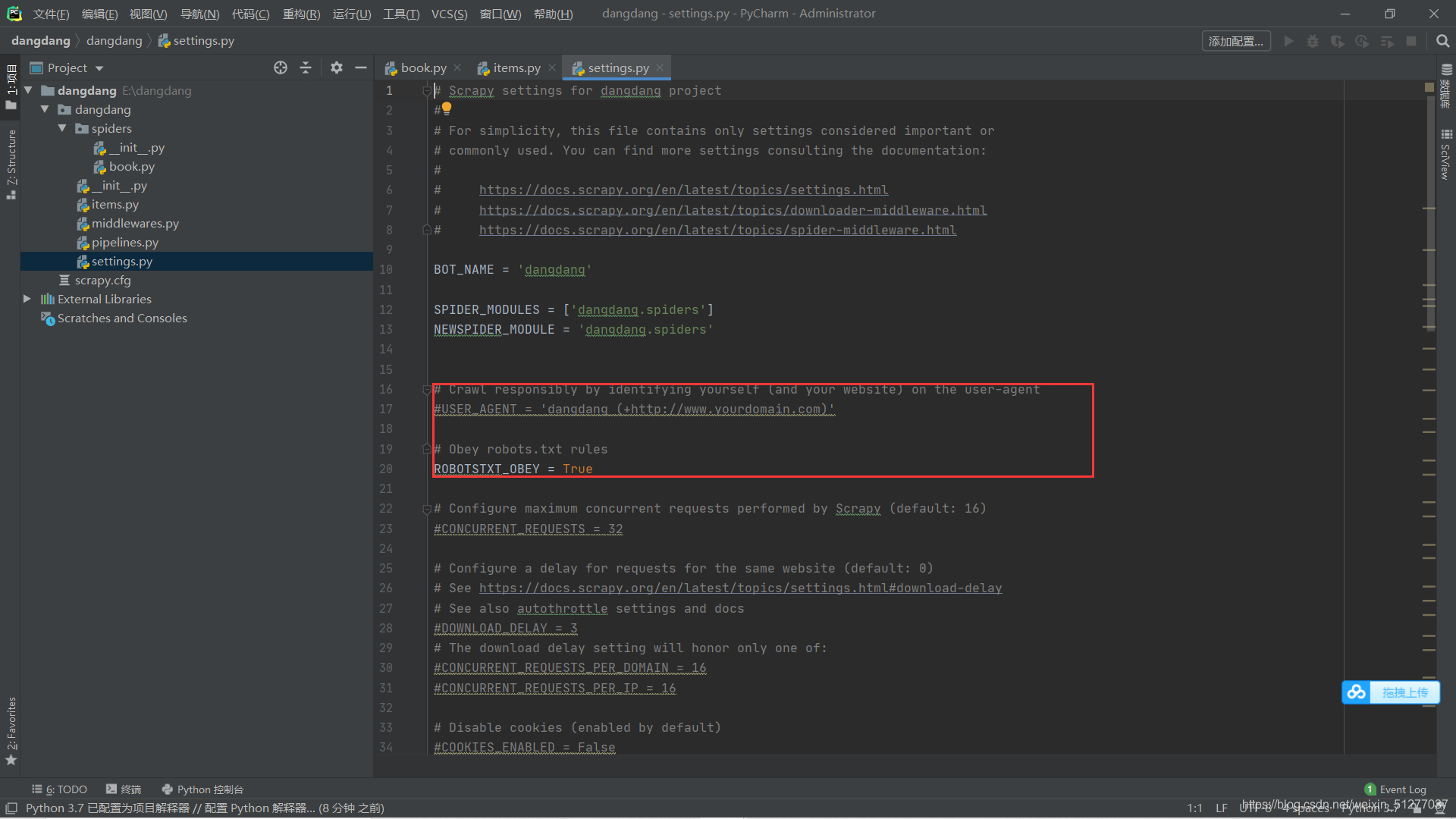
改成这样:(也就是取消遵守爬虫协议)
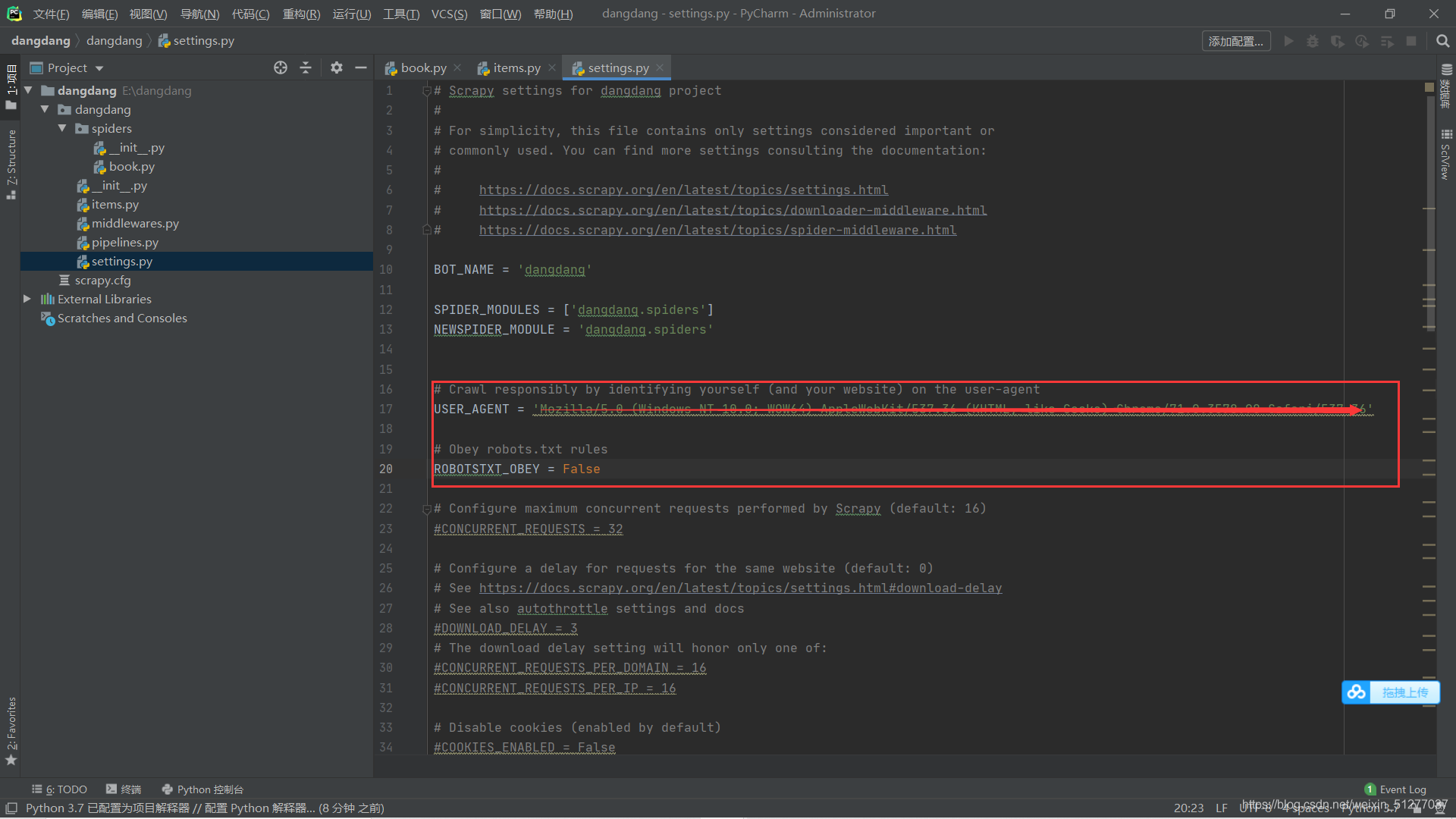
代码如下
Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = '~~Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'~~ (请求头改成自己的)
Obey robots.txt rules
ROBOTSTXT_OBEY = False
最后一步
打开item.py文件修改
添加以下参数:
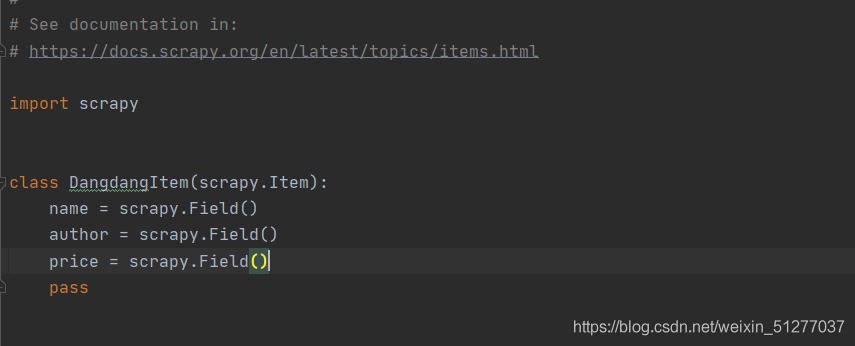
name = scrapy.Field()
author = scrapy.Field()
price = scrapy.Field()
如图:
三、运行爬虫
创建main.py(通过这个运行整个爬虫程序)
我们需要知道在Scrapy中有一个可以控制终端命令的模块cmdline,能操控终端
但是此方法需要传入列表的参数。
填入:
from scrapy import cmdline
cmdline.execute(['scrapy','crawl','dangdang'])
运行这个main.py就成功了!
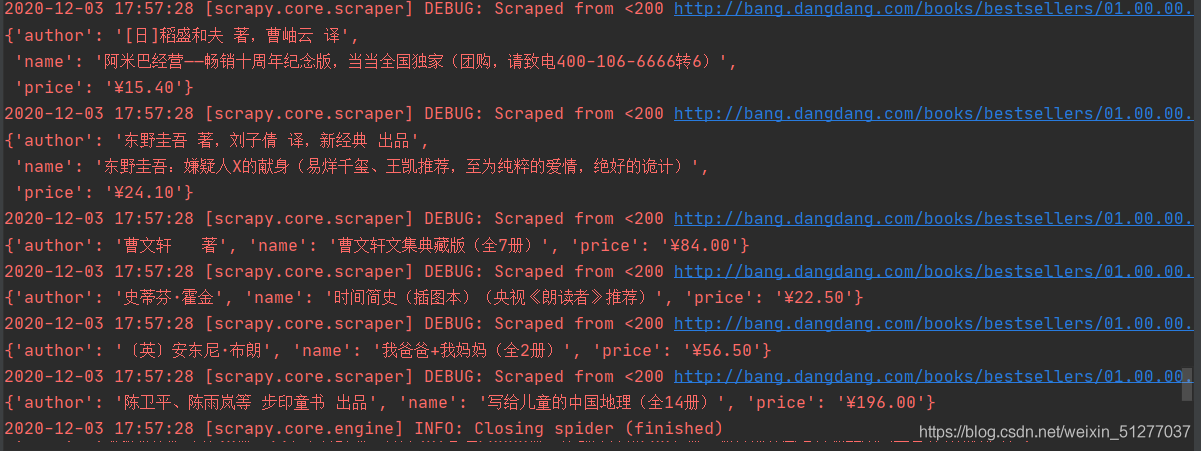
四、保存为csv文件
要是想把爬取内容以表格形式保存
三行代码就可以解决,这也是scrapy的方便之处。
打开settings.py文件,在末尾添加代码:
FEED_URI='./%(name)s.csv'
FEED_FORMAT='csv'
FEED_EXPORT_ENCODING='ansi'
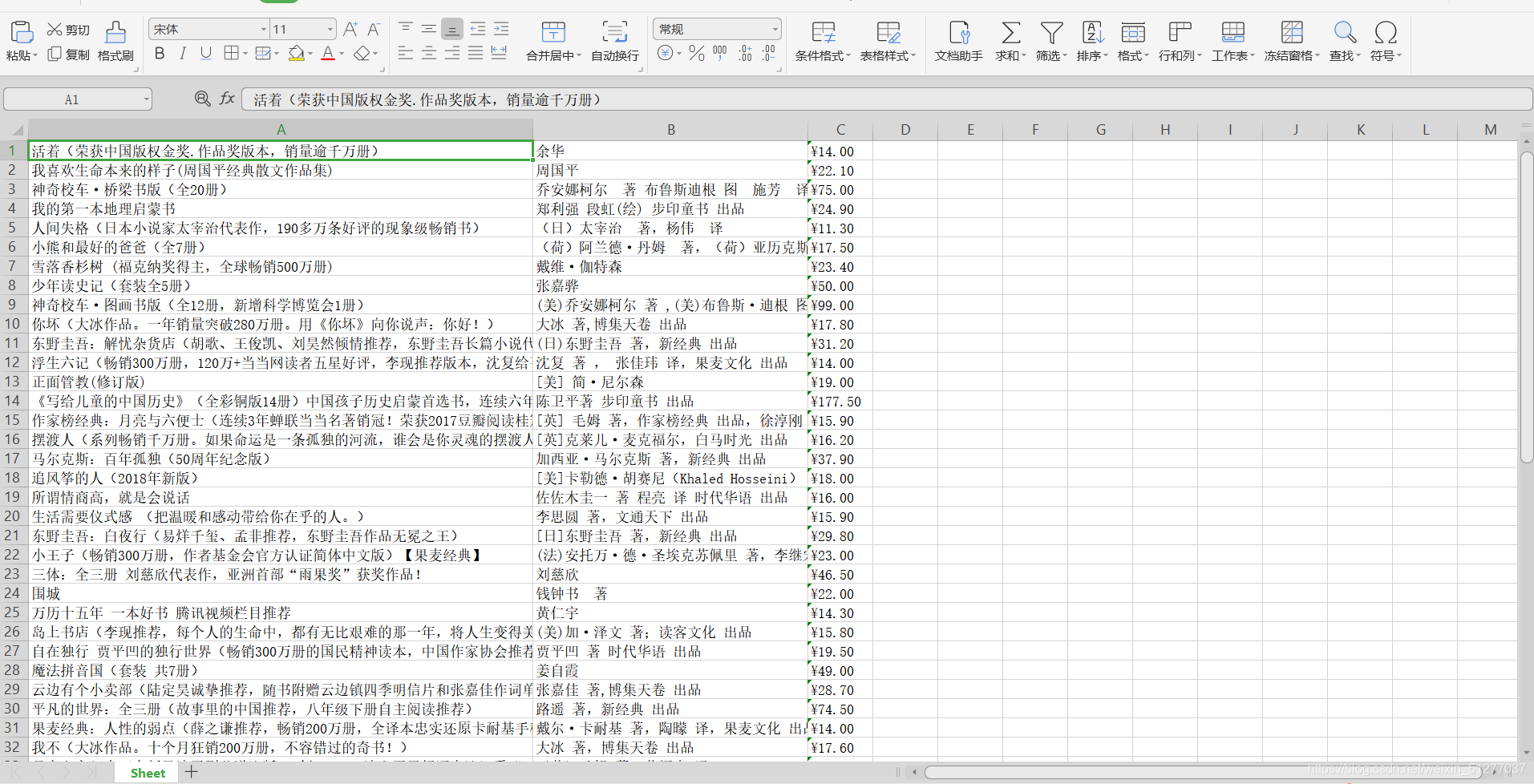 看起来美观很多。
看起来美观很多。
运行过程中可能会有各种报错,也是正常的,不要紧,一步步debug就会成功的。
谢谢支持~